THU《操作系统》学习笔记——实验0 x86-32硬件介绍和操作系统实验环境准备
1.了解OS实验
ucore的运行环境可以是真实的X86计算机,不过考虑到调试和开发的方便,我们可采用X86硬件模拟器,比如QEMU、BOCHS、VirtualBox、VMware Player等。ucore的开发环境主要是GCC中的gcc、gas、ld和MAKE等工具,也可采用集成了这些工具的IDE开发环境Eclipse-CDT等。在分析源代码上,可以采用Scitools提供的understand软件(跨平台),windows环境上的source insight软件,或者基于emacs+ctags,vim+ctags等,都可以比较方便在在一堆文件中查找变量、函数定义、调用/访问关系等。软件开发的版本管理可以采用GIT、SVN等。比较文件和目录的不同可发现不同实验中的差异性和进行文件合并操作,可使用meld、kdiff3、UltraCompare等软件。调试(deubg)实验有助于发现设计中的错误,可采用gdb(配合qemu)等调试工具软件。并可整个实验的运行环境和开发环境既可以在Linux或Windows中使用。推荐使用Linux环境。
那我们准备如何一步一步来实现ucore呢?根据一个操作系统的设计实现过程,我们可以有如下的实验步骤:
- 启动操作系统的bootloader,用于了解操作系统启动前的状态和要做的准备工作,了解运行操作系统的硬件支持,操作系统如何加载到内存中,理解两类中断--“外设中断”,“陷阱中断”等;
- 物理内存管理子系统,用于理解x86分段/分页模式,了解操作系统如何管理物理内存;
- 虚拟内存管理子系统,通过页表机制和换入换出(swap)机制,以及中断-“故障中断”、缺页故障处理等,实现基于页的内存替换算法;
- 内核线程子系统,用于了解如何创建相对与用户进程更加简单的内核态线程,如果对内核线程进行动态管理等;
- 用户进程管理子系统,用于了解用户态进程创建、执行、切换和结束的动态管理过程,了解在用户态通过系统调用得到内核态的内核服务的过程;
- 处理器调度子系统,用于理解操作系统的调度过程和调度算法;
- 同步互斥与进程间通信子系统,了解进程间如何进行信息交换和共享,并了解同步互斥的具体实现以及对系统性能的影响,研究死锁产生的原因,以及如何避免死锁;
- 文件系统,了解文件系统的具体实现,与进程管理等的关系,了解缓存对操作系统IO访问的性能改进,了解虚拟文件系统(VFS)、buffer cache和disk driver之间的关系。

2.操作系统实验环境的准备
1.通过虚拟机使用Linux实验环境。这是最简单的一种通过虚拟机方式使用Linux并完成OS各个实验的方法,不需要安装Linux操作系统和各种实验所需开发软件。首先安装VirtualBox 虚拟机软件(有windows版本和其他OS版本,可到 http://www.virtualbox.org/wiki/Downloads 下载),然后在百度云盘 http://pan.baidu.com/s/11zjRK 上下载一个已经安装好各种所需编辑/开发/调试/运行软件的Linux实验环境的VirtualBox虚拟硬盘文件(mooc-os-2015.vdi.xz,包含一个虚拟磁盘镜像文件和两个配置描述文件,下载此文件的网址址见 https://github.com/chyyuu/ucore_lab 下的README中的描述)。用2345好压软件(有windows版本,可到http://www.haozip.com 下载。一般软件解压不了xz格式的压缩文件)先解压到C盘的vms目录下即: C:\vms\mooc-os-2015.vdi
解压后这个文件所占用的硬盘空间为6GB左右。在VirtualBox中创建新虚拟机(设置64位Linux系统,指定配置刚解压的这个虚拟硬盘mooc-os-2015.vdi),就可以启动并运行已经配置好相关工具的Linux实验环境了。
如果提示用户“moocos”输入口令时,只需简单敲一个空格键和回车键即可,即账户密码为一个空格。然后就进入到开发环境中了。实验内容位于ucore_lab目录下。
2.使用蓝桥云课提供的Ucore线上实验环境。这是最简单的且不用自行安装环境的方法,网址为 https://www.lanqiao.cn/courses/221 ,需要花钱购买蓝桥云课会员(399元/年),才可以保存你的系统,否则无法保存上次写过的内容。
3.x86-32硬件介绍
3.1 了解X86-32硬件-运行模式
首先x86是个简称,具体是指Intel 80386 CPU,它是Intel 32位的CPU,在上世纪90年代初使用得非常广泛,它有四种运行模式:实模式、保护模式、SMM模式和虚拟8086模式。而在Ucore操作系统实验中涉及到的是实模式和保护模式。
实模式是为了兼容早期的Intel 8086的机器做的一种模式,80386加电一启动之后就处于实模式状态,在这个时候它的寻址空间不超过1MB,且无法发挥Intel 80386以上级别的32位CPU的4G内存管理机制。比如早期微软的DOS系统就运行在实模式环境中。
第一:保护模式为32位的寻址空间,它有4GB的寻址空间。
第二:保护模式提供了分页和分段机制,这两种机制能够让软件放在不同的特权级,访问不同的空间,且他们相互之间是隔离的。这种机制就可以使得应用程序运行在较低的级别,应用程序被限制运行在一个有限的空间里面,不会破坏操作系统,不会访问特权指令。这就是保护模式提供的一种功能。

3.2 了解x86-32硬件-内存架构
对于80386机器而言,它对每一个类型单元都有一个编制,地址是访问内存空间的一个索引。既然80386是一个32位的机器,所以它的寻址能力为2^32=4GB。
在计算机里有很多不同的寻址方式,首先CPU硬件有一个物理内存。物理内存是CPU发出一个寻址的一个地址请求,这个请求发到总线上用于访问计算机系统中的所有内存和外设的最终地址。
计算机内存条里的地址就是所谓的物理地址,访问一个物理地址即为读取内存条中的一个内存单元内容。
线性地址是80386机器里面引用的一种地址。由于有了段模式,让每一个应用程序都有一个相对独立地址空间,每个运行的应用程序都认为它自己独占了整个计算机的地址空间,这个地址空间称作线性地址空间。线性地址空间是靠段模式和页模式集中在一起保护来实现的。
逻辑地址空间是应用程序直接使用地址空间。
如果80386的段机制启动、页机制未启动,逻辑地址通过段机制进行映射处理能转变成线性地址,页机制没有启动,在这里线性地址就等于物理地址。而如果页机制启动了,这个时候线性地址会通过页机制映射处理转变为物理地址。可以看出来,段机制和页机制就是一种地址的映射关系。

3.3 了解x86-32硬件-寄存器
CPU有一组寄存器来存储数据,寄存器分为八组,通常用得最多的是通用寄存器,跟段相关的是段寄存器,指令指针寄存器EIP和寻址有关,还有标志寄存器Eflags,最后四组寄存器一般开发应用程序用不到,但是开发OS需要用到。因为这些特殊寄存器用来完成特殊的功能,比如说让系统从实模式进入保护模式,让它启动分页,分段等等。后面的四组寄存器可以说是专门用来给操作系统这样的一些系统软件来使用的。
- 通用寄存器
- 段寄存器
- 指令指针寄存器
- 标志寄存器
- 控制寄存器
- 系统地址寄存器
- 调试寄存器
- 测试寄存器



需要再重点记录一下段寄存器和指令寄存器,标志寄存器的内容。其中段寄存器是用来寻址的,CS里面的值代表特定含义,在实模式和保护模式下它的含义不一样,这个需要注意。
指令寄存器主要是指EIP,对于16位 8086 CPU而言,它是由CS和IP共同决定地址,CS和IP合在一起可以访问1M的内存地址空间。但如果是到了保护模式的32位的CS和EIP就有了新的含义,它们结合在一起可以完成对32位内存地址空间的寻址, EIP表示的是段内偏移地址。
标志寄存器主要指Eflags,标志寄存器很有用,比如做加法是否溢出,所有这些标志都存储在标志寄存器里。除此之外还有特殊的一些位,比如是否允许中断等,这些都是由Eflags里的特定的BIT来表示的,而有一些BIT不能由应用程序修改,而只能由操作系统来修改,这属于运行在特权态中的操作系统才有能力去完成对标志位的修改。
4.Ucore部分编程技巧
4.1 Ucore中的面向对象编程
Ucore主要基于C语言设计,采用了一定的面向对象编程方法。
例如图中的物理内存管理器,pmm_manager,这个管理器有很多一些函数的实现,它的表示是用函数指针的方式来实现。实际上对外暴露给需要访问物理内存管理器这些调用者一个统一的接口,这个接口不会改变。如果有不同的物理内存管理方法,比如说不同连续内存分配算法,那么可以保持同样接口,但是它实现不一样。这个带来统一的接口,但是它的实现细节不一样,这里用到的就是面向对象设计的一种原则。
4.2 Ucore中的通用数据结构(双向循环链表)
在操作系统开发中,我们利用双向循环链表把各种数据结构链接在一起。首先,常见的双向循环链表的节点是这样的:
typedef struct Node{
ElemType data;
struct Node *prev;
struct Node *next;
}foo;
但是这样定义双向循环链表,需要为每种特定的数据结构类型定义针对这个数据的特定链表插入,删除等各种操作,会导致代码冗余。这使得我们建立的数据结构不具有通用性,那么我们有没有更好的办法?
//通用的双向链表
struct list_entry_t{
struct list_entry_t *prev,*next;
};
我们可以定义一个通用的双向链表,比如上面所写的list_entry_t,里面依然有prev和next,但是这个prev和next并不是特定结构的指针,它是一个通用结构指针。那么怎么用list_entry_t建立起双向循环链表结构呢?可以看下图。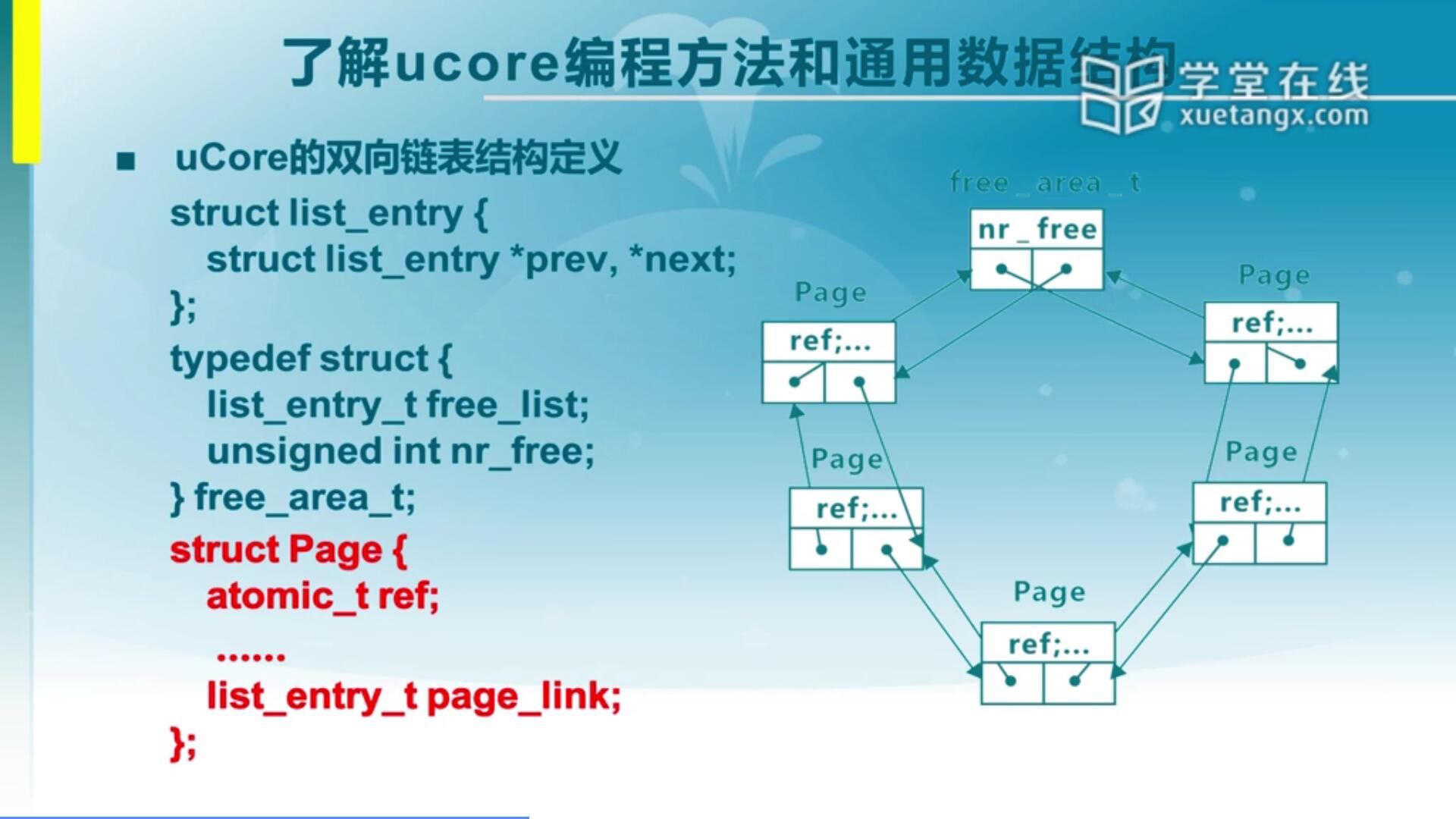
这个双向链表结构包含了free_area_t和page两种不同的struct。free_area_t里面包含了free_list和nr_free,free_list就是一个list_entry_t,它的中间元素叫nr_free,这是一个它的特定元素。free_list就是list_entry_t这种数据结构,那么它怎么和page连接在一起呢?
来看看page这个结构,我们把page这个结构也是定义了一个list_entry_t的成员page_link,其他的是它自己的一些成员变量,或者说它的特定域。page和free_area_t它们都有了list_entry_t这个数据结构之后,就可以通过它的prev和next建立起双向连接关系。这里面即满足了不同类型数据结构的特定成员变量的表示,而且在设计链接关系时用的是一种通用的结构来表示,这是通用的双向链表的表示方式,它在Ucore里大量存在。有了这种方式之后可以更简洁,更灵活地来表示不同的资源,以及资源之间的关系。
//通用链表结构同样可以写链表操作函数,比如初始化,插入,删除
list_init(list_entry_t *elm)
list_add_after和list_add_before
list_del(list_entry_t *listelm)
还有很重要的一点,就是怎么根据free_list或者page_link来找到它所在的宿主数据结构(struct)的首地址?这里实际上有一定技巧。
//访问链表节点所在的宿主数据结构
free_area_t free_area;
list_entry_t *le = &free_area.free_list;
//此处的list_next(le)是一个访问next节点的函数,访问了le的next节点
while((le=list_next(le))!=&free_area.free_list){
struct Page* p=le2page(le,page_link);
}
上面的代码是以free_area为头节点,去查找所有free_area管理的page,它看起来是一个轮询的方式,但是有一点不一样。这里使用到了一个特殊的宏,叫le2page(le to page)。通过le2page来找到某一个page变量的头指针在什么地方。那么le2page是怎么实现的呢?
/*le2page参数包含一个指针le,一个member,这个指针le是链表节点所在数据结构的指
针,member是它的名字,比如page里它叫page_link。le2page它又是由另一个宏to_struct
来执行的。
这个to_struct在这写的三个参数,一个是le,一个是struct Page,一个是member。
那么这个struct page是怎么体现的呢,从le2page这个名字可以看出来我们这个宏它对应
page这个特定的数据结构,所以这里的参数传的是struct page这一个特定的数据结构。*/
#define le2page(le,member) to_struct((le),struct Page,member)
/*to_struct这里ptr是指针,type是想要转换成的struct类型,member是一个struct中的
成员。对于le2page传过来的参数,是让le的地址,减去link_page也就是le自身相对于
struct page首地址的偏移量,从而获得首地址。为什么这里使用char*?是因为char*做加
1或减1,它的内存地址偏移正好是1字节,若用别的类型如int*,它加1或减1会偏移4字节。
offsetof得到member相应字节的偏移量,比如偏移量为4,用(char*)ptr-4正好是内存地址
减去4,从而得到正确的地址结果。*/
#define to_struct(ptr,type,member) ((type*)((char*)(ptr)-offsetof(type,member)))
/*offsetof用于求member在type中的偏移量。这里的0和type*合在一起基址为0,然后成为
一个type类型的变量,然后member所在的地址就代表member这个成员变量在type这个类型
中的偏移量。*/
#define offsetof(type,member) ((size_t)(&(type*)0)->member))
这三个宏总的来说,le2page是带有三个信息:宿主数据结构的链表节点的指针、宿主数据结构的类型、链表节点指针在宿主数据结构中对应的名字,得到这三个信息之后,将它们传入to_struct,然后经过offsetof这里的表达式求出偏移量,最后让链表节点指针的地址减去偏移量,就可以获得宿主数据结构的头指针(首地址)。
实验零 总结
实际上在看到这些C代码的宏定义时,我是懵逼的,自己打开VS实验了这些代码和到处问大佬弄了一晚上才弄大概清楚,这些C代码究竟为啥能算出宿主结构的首地址。发现我的C语言水平实在是太差了,然后在没有学计算机组成原理这门前置知识的情况下来学操作系统,还是有些方面会感到疑惑,开始感到学习得有些吃力了,不过这也说明了学习OS的确是困难的。遇到困难当然要睡大觉,不是。是当然要迎难而上!(╬▔皿▔)╯不过在学习OS的同时还得抽点时间看看CSAPP和计组,补一补前置知识才行了。感觉学习写OS,顺便也能提升自己的C语言水平呢,继续加油叭!



