Redis学习笔记(3):Hash类型基本API
1. Hash类型基本介绍
Hash类型是编程语言里最常见的数据结构之一了,几乎所有编程语言都会提供Hash类型Hash有很多中文叫法,最常见的是哈希和字典。
在Redis中,Hash类型是指键值本身是一对键值对结构,value={field1,value1},{field2,value2}…。也就是说一个Hash类型,key是指这个Hash类型它的名字,value是一个键值对,但是这个键值对的键名为了区分于key,我们不叫key,而是叫field(这个原因是我猜的),然后一个Hash类型可以拥有多个value(即field-value对)。
本篇依然有金毛站长无聊瞎搞试出的奇怪现象与对该现象的源码分析,如果你已经会了API的话可以跳到这段看个乐子哦🍭🍭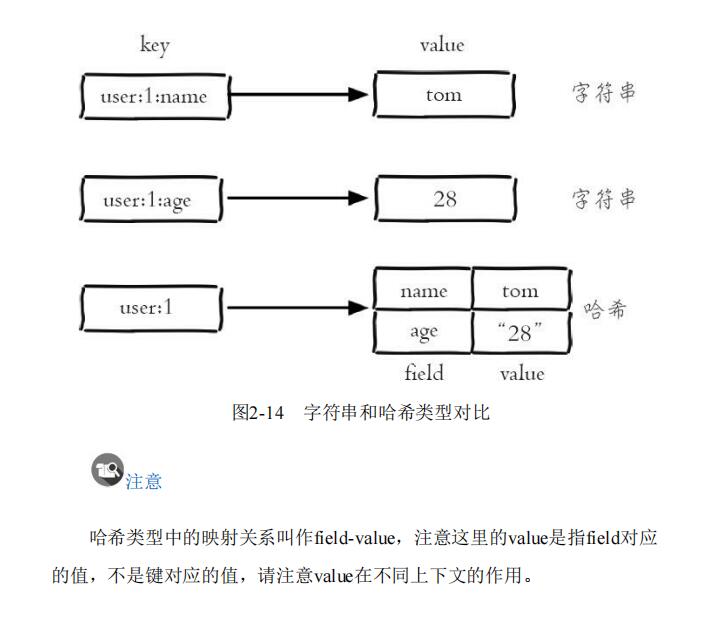
2.Hash类型内部编码简介
Hash类型有两种内部编码:
·ziplist(压缩列表):当哈希类型元素个数小于等于hash-max-ziplist-entries 配置(默认512个)、同时所有值都小于等于hash-max-ziplist-value配置(默认64 字节)时,Redis会使用ziplist作为哈希的内部实现,ziplist使用更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面比hashtable更加优秀。
当哈希类型无法满足listpack的条件时,Redis会使用hashtable作为哈希的内部实现,因为此时ziplist的读写效率会下降,而hashtable的读写时间复杂度为O(1)。
注:Redis的Unstable和7.0版本将使用listpack替代hash的ziplist。由于ziplist中有着致命的缺陷-连锁更新,在极端条件下会有着极差的性能,导致整个redis响应变慢。listpack是ziplist结构的改进版,在存储空间上更加节省,而且比ziplist也更精简。
3. Hash基本API
hset命令:
hset {key} {field} {value} ,设置值,不存在key则创建该key并添加输入的”field-value”键值对,若该key存在而”field-value”不存在则添加该”field-value”键值对,若已经存在则更新value。添加”field-value”键值对成功则返回1,无添加(如只做更新)则返回0。
# 示例
127.0.0.1:6379> hset uid v1 1
(integer) 1
127.0.0.1:6379> hset uid v1 0
(integer) 0
# hsetnx在field不存在的情况下才能设置值成功
127.0.0.1:6379> hsetnx uid v1 3
(integer) 0
# v1依然是0
127.0.0.1:6379> hget uid v1
"0"
#v3不存在,则添加成功返回1
127.0.0.1:6379> hsetnx uid v3 3
(integer) 1
hmset命令:
hmset {key} {field1} {value1} {field2} {value2}… ,批量设置值,成功返回OK。
# 示例
127.0.0.1:6379> hmset uid v1 1 v2 2 v3 3
OK
hget命令:
hget {key} {field} ,获取指定的hash下的”field-value”对的value,存在返回对应的值,不存在返回nil。
# 示例
127.0.0.1:6379> hset uid v2 2
(integer) 1
127.0.0.1:6379> hget uid v2
"2"
127.0.0.1:6379> hget uid v4
(nil)
hmget命令:
hmget {key} {field1} {value1} {field2} {value2}… ,批量获取值,存在返回对应的值,不存在返回nil。
# 示例
127.0.0.1:6379> hmset uid v1 1 v2 2 v3 3
OK
127.0.0.1:6379> hmget uid v1 v2 v3
1) "1"
2) "2"
3) "3"
127.0.0.1:6379> hmget uid v3 v4
1) "3"
2) (nil)
hdel命令:
hdel {key} {field1} {field2}… ,删除field,可以批量删除,返回结果为成功删除field的个数。
# 示例
127.0.0.1:6379> hset uid v4 1
(integer) 1
127.0.0.1:6379> hset uid v5 3
(integer) 1
127.0.0.1:6379> hdel uid v4 v5
(integer) 2
hlen命令:
hlen {key} ,返回该key对应的hash类型的field个数。
# 示例
127.0.0.1:6379> hset testid v1 1
(integer) 1
127.0.0.1:6379> hset testid v2 2
(integer) 1
127.0.0.1:6379> hlen testid
(integer) 2
hexists命令:
hexists {key} {field} ,判断field是否存在,存在返回1,不存在返回0。
127.0.0.1:6379> hset uid v1 1
(integer) 1
127.0.0.1:6379> hexists uid v1
(integer) 1
127.0.0.1:6379> hexists uid v2
(integer) 0
hkeys命令:
hkeys {key} ,返回该key指定的hash类型下的所有field(这个命令叫hfields更恰当),不存在返回(empty array)。
# 示例
127.0.0.1:6379> hmset uid v1 1 v2 2
OK
127.0.0.1:6379> hkeys uid
1) "v1"
2) "v2"
127.0.0.1:6379> hkeys name
(empty array)
hvals命令:
hkeys {key} ,返回该key指定的hash类型下的所有value,不存在返回(empty array)。
# 示例
127.0.0.1:6379> hmset uid v1 1 v2 2
OK
127.0.0.1:6379> hvals uid
1) "1"
2) "2"
127.0.0.1:6379> hvals name
(empty array)
hgetall命令:
hgetall {key} ,返回该key指定的hash类型下的所有field-value,不存在返回(empty array)。
# 示例
127.0.0.1:6379> hmset uid v1 1 v2 2
OK
127.0.0.1:6379> hgetall uid
1) "v1"
2) "1"
3) "v2"
4) "2"
127.0.0.1:6379> hgetall name
(empty array)
在使用hgetall时,如果哈希元素个数比较多,会存在阻塞Redis的可能。如果开发人员只需要获取部分field,可以使用hmget,如果一定要获取全部field-value,可以使用hscan命令,该命令会渐进式遍历哈希类型。渐进式遍历命令包含有scan,hscan,sscan,zscan,金毛站长会仔细学习后放到以后的篇章专门提起。
hincrby/hincrbyfloat命令:
hincrby/hincrbyfloat {key} {field} {increment} ,hincrby和hincrbyfloat,就像incrby和incrbyfloat命令一样,一个是增加整数,一个是增加浮点数,但是它们的作用域是filed。对一个value使用hincrby,该value和increment需要是整数,否则报错;对一个value使用hincrbyfloat,该value和increment需要是数字,否则报错。
# 示例
127.0.0.1:6379> hmset uid v1 1 v2 1.5
OK
127.0.0.1:6379> hincrby uid v1 1
(integer) 2
127.0.0.1:6379> hincrby uid v1 1.5
(error) ERR value is not an integer or out of range
127.0.0.1:6379> hincrbyfloat uid v2 1.5
"3"
127.0.0.1:6379> hincrbyfloat uid v2 abc
(error) ERR value is not a valid float
127.0.0.1:6379> hincrbyfloat uid v1 1.5
"3.5"
127.0.0.1:6379> hincrbyfloat uid v2 1e5
"100003"
下图是哈希类型命令的时间复杂度。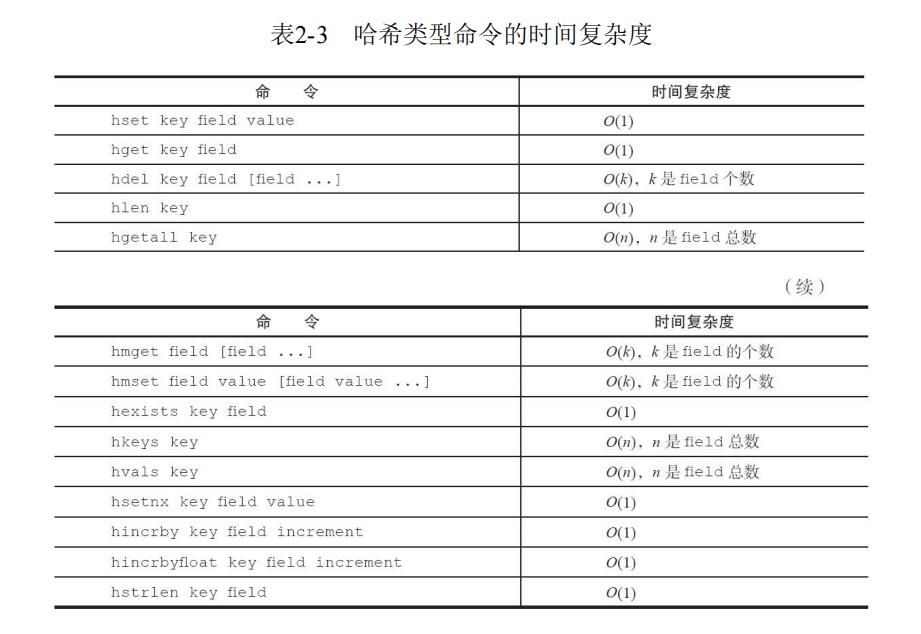
4. 使用场景
1.缓存用户信息
可以将关系型数据库中记录的用户信息使用Hash类型进行缓存。相比于使用字符串序列化缓存用户信息,哈希类型变得更加直观,并且在更新操作上会更加便捷。可以将每个用户的id定义为键后缀,多对field-value对应每个用户的属性。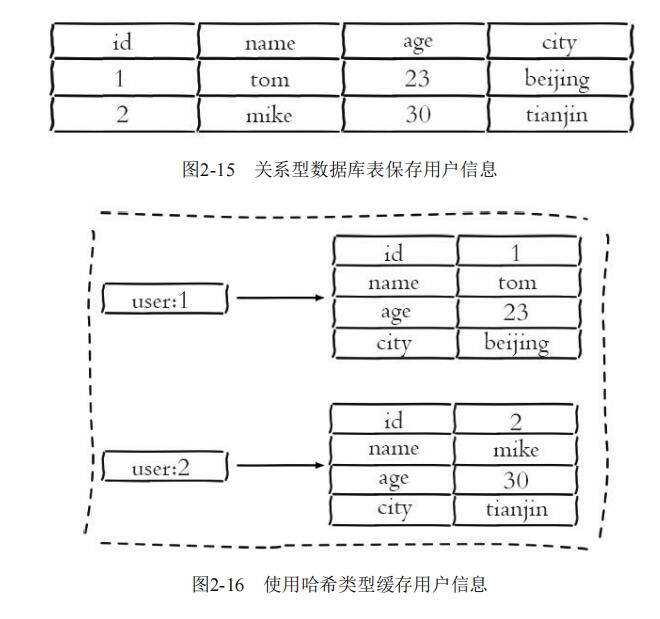
但是需要注意的是哈希类型和关系型数据库有两点不同之处:
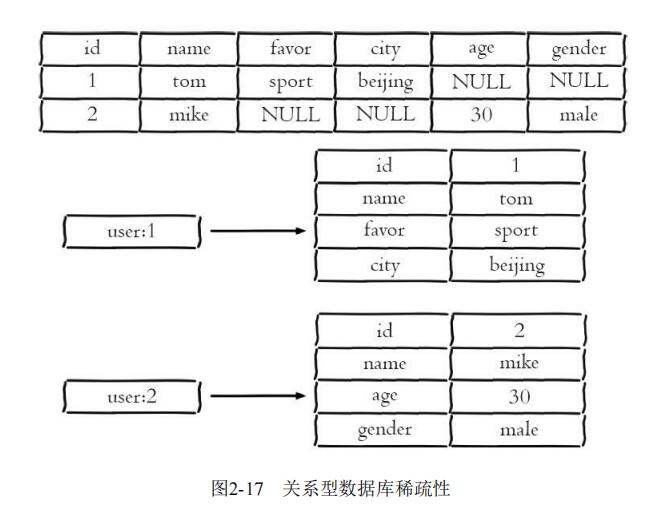
开发人员需要将两者的特点搞清楚,才能在适合的场景使用适合的技术。到目前为止,我们已经能够用三种方法缓存用户信息,下面给出三种方案的实现方法和优缺点分析:
1. 原生字符串类型:每个属性一个键。
set user:1:name tom
set user:1:age 23
set user:1:city beijing
优点:简单直观,每个属性都支持更新操作。
缺点占用过多的键,内存占用量较大,同时用户信息内聚性比较差, 所以此种方案一般不会在生产环境使用。
2. 序列化字符串类型:将用户信息序列化后用一个键保存。
set user:1 serialize(userInfo)
优点:简化编程,如果合理的使用序列化可以提高内存的使用效率。
缺点:序列化和反序列化有一定的开销,同时每次更新属性都需要把全部数据取出进行反序列化,更新后再序列化到Redis中。
3. 哈希类型:每个用户属性使用一对field-value,但是只用一个键保存。
hmset user:1 name tomage 23 city beijing
优点:简单直观,如果使用合理可以减少内存空间的使用。
缺点:要控制哈希在listpack和hashtable两种内部编码的转换,hashtable会消耗更多内存。
5. 关于hash的奇怪现象与源码分析
没错,小破站站长金毛又无聊瞎搞Redis中的hash试出了奇怪的现象!不过这次的奇怪现象仅有一个,那就是:hincrbyfloat无法改变内部编码。什么意思呢?就是说值超过hash_max_listpack_value(默认64字节),内部编码类型应该从listpack转变为hashtable,但是使用incrbyfloat无论变得多大都不会改变内部编码。
# 现象如下
127.0.0.1:6379> hset uid v1 1
(integer) 1
127.0.0.1:6379> hincrbyfloat uid v1 1e65
"99999999999999999209038626283633850822756121694230455365568299008"
# 使用hincrbyfloat令v1增加至长度65后
127.0.0.1:6379> hstrlen uid v1
(integer) 65
127.0.0.1:6379> object encoding uid
"ziplist"
127.0.0.1:6379> hincrbyfloat uid v1 1e1000
"100000000000000005803618566936201790133866835549086831587374......959939072"
127.0.0.1:6379> hstrlen uid v1
(integer) 1001
127.0.0.1:6379> object encoding uid
"ziplist"
127.0.0.1:6379> hset uid v1 aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
(integer) 0
127.0.0.1:6379> hstrlen uid v1
(integer) 74
127.0.0.1:6379> object encoding uid
"hashtable"
为什么会出现这种现象呢?金毛站长带着疑惑打开了t_hash.c文件进行源码分析,让我们来看看hincrbyfloat的源代码:
void hincrbyfloatCommand(client *c) {
long double value, incr;
long long ll;
robj *o;
sds new;
unsigned char *vstr;
unsigned int vlen;
if (getLongDoubleFromObjectOrReply(c,c->argv[3],&incr,NULL) != C_OK) return;
if ((o = hashTypeLookupWriteOrCreate(c,c->argv[1])) == NULL) return;
if (hashTypeGetValue(o,c->argv[2]->ptr,&vstr,&vlen,&ll) == C_OK) {
if (vstr) {
if (string2ld((char*)vstr,vlen,&value) == 0) {
addReplyError(c,"hash value is not a float");
return;
}
} else {
value = (long double)ll;
}
} else {
value = 0;
}
value += incr;
if (isnan(value) || isinf(value)) {
addReplyError(c,"increment would produce NaN or Infinity");
return;
}
char buf[MAX_LONG_DOUBLE_CHARS];
int len = ld2string(buf,sizeof(buf),value,LD_STR_HUMAN);
new = sdsnewlen(buf,len);
//重点
hashTypeSet(o,c->argv[2]->ptr,new,HASH_SET_TAKE_VALUE);
addReplyBulkCBuffer(c,buf,len);
signalModifiedKey(c,c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_HASH,"hincrbyfloat",c->argv[1],c->db->id);
server.dirty++;
/* Always replicate HINCRBYFLOAT as an HSET command with the final value
* in order to make sure that differences in float precision or formatting
* will not create differences in replicas or after an AOF restart. */
robj *newobj;
newobj = createRawStringObject(buf,len);
rewriteClientCommandArgument(c,0,shared.hset);
rewriteClientCommandArgument(c,3,newobj);
decrRefCount(newobj);
}
这里有一句hashTypeSet,看名字是和哈希内部编码有关,进去看看它的实现是什么样的:
int hashTypeSet(robj *o, sds field, sds value, int flags) {
int update = 0;
if (o->encoding == OBJ_ENCODING_LISTPACK) {
unsigned char *zl, *fptr, *vptr;
zl = o->ptr;
fptr = lpFirst(zl);
if (fptr != NULL) {
fptr = lpFind(zl, fptr, (unsigned char*)field, sdslen(field), 1);
if (fptr != NULL) {
/* Grab pointer to the value (fptr points to the field) */
vptr = lpNext(zl, fptr);
serverAssert(vptr != NULL);
update = 1;
/* Replace value */
zl = lpReplace(zl, &vptr, (unsigned char*)value, sdslen(value));
}
}
if (!update) {
/* Push new field/value pair onto the tail of the listpack */
zl = lpAppend(zl, (unsigned char*)field, sdslen(field));
zl = lpAppend(zl, (unsigned char*)value, sdslen(value));
}
o->ptr = zl;
/* Check if the listpack needs to be converted to a hash table */
//关键
if (hashTypeLength(o) > server.hash_max_listpack_entries)
hashTypeConvert(o, OBJ_ENCODING_HT);
} else if (o->encoding == OBJ_ENCODING_HT) {
dictEntry *de = dictFind(o->ptr,field);
if (de) {
sdsfree(dictGetVal(de));
if (flags & HASH_SET_TAKE_VALUE) {
dictGetVal(de) = value;
value = NULL;
} else {
dictGetVal(de) = sdsdup(value);
}
update = 1;
} else {
sds f,v;
if (flags & HASH_SET_TAKE_FIELD) {
f = field;
field = NULL;
} else {
f = sdsdup(field);
}
if (flags & HASH_SET_TAKE_VALUE) {
v = value;
value = NULL;
} else {
v = sdsdup(value);
}
dictAdd(o->ptr,f,v);
}
} else {
serverPanic("Unknown hash encoding");
}
/* Free SDS strings we did not referenced elsewhere if the flags
* want this function to be responsible. */
if (flags & HASH_SET_TAKE_FIELD && field) sdsfree(field);
if (flags & HASH_SET_TAKE_VALUE && value) sdsfree(value);
return update;
}
我们看到这里只有一个判断”if (hashTypeLength(o) > server.hash_max_listpack_entries)hashTypeConvert(o, OBJ_ENCODING_HT);”,这个判断只判断了field的数量是不是大于限制(512),而并没有对于值长度的判断。所以这也就解释了为什么无论hincrbyfloat能有多长都不会修改内部编码。另外,hincrby的代码也是一样的,只判断了数量,但由于整数有限制并不会达到65字节,所以一般来说不改源码,hincrby是不会出现这种奇怪现象的。
6. 杂谈
今天花了半天的时间来研究这个hincrby和hincrbyfloat为什么不判断value的长度,思来想去都想不到一个很好的理由,所以就开始着手了修这个可能的bug。虽然只添加了6行代码,但花了很多时间来确定要不要这么写,理由是什么。因为社恐又怕PR了因为没必要被老外说教。不过经过很长时间的思想斗争,现在还是带着翻译来的撇脚英文commit来PR了。反正无论成不成功,我都不亏鸭!成功了成为贡献者,不成功还能得到大佬的解答。嘻嘻!
https://github.com/redis/redis/pull/10479
欢迎来看github对线现场。



