THU《操作系统》学习笔记——实验2:物理内存管理
1. 了解x86保护模式中的特权级
首先我们来了解下X86的特权级,我们先要知道的就是CPU到底提供了几种特权级;然后我们的程序在跑的时候,CPU当前处于哪个特权级,也就是说应用程序到底处于什么特权级,我们怎么知道应用程序是在内核态还是用户态跑的;第三个呢,我们说我们的应用程序跑在用户态,但可能过了一会儿又跑到内核态,这个来回的切换涉及到特权级的切换,这个切换过程是怎么实现的,也是我们这一节要学习的内容。
1.1 了解不同特权级的差别
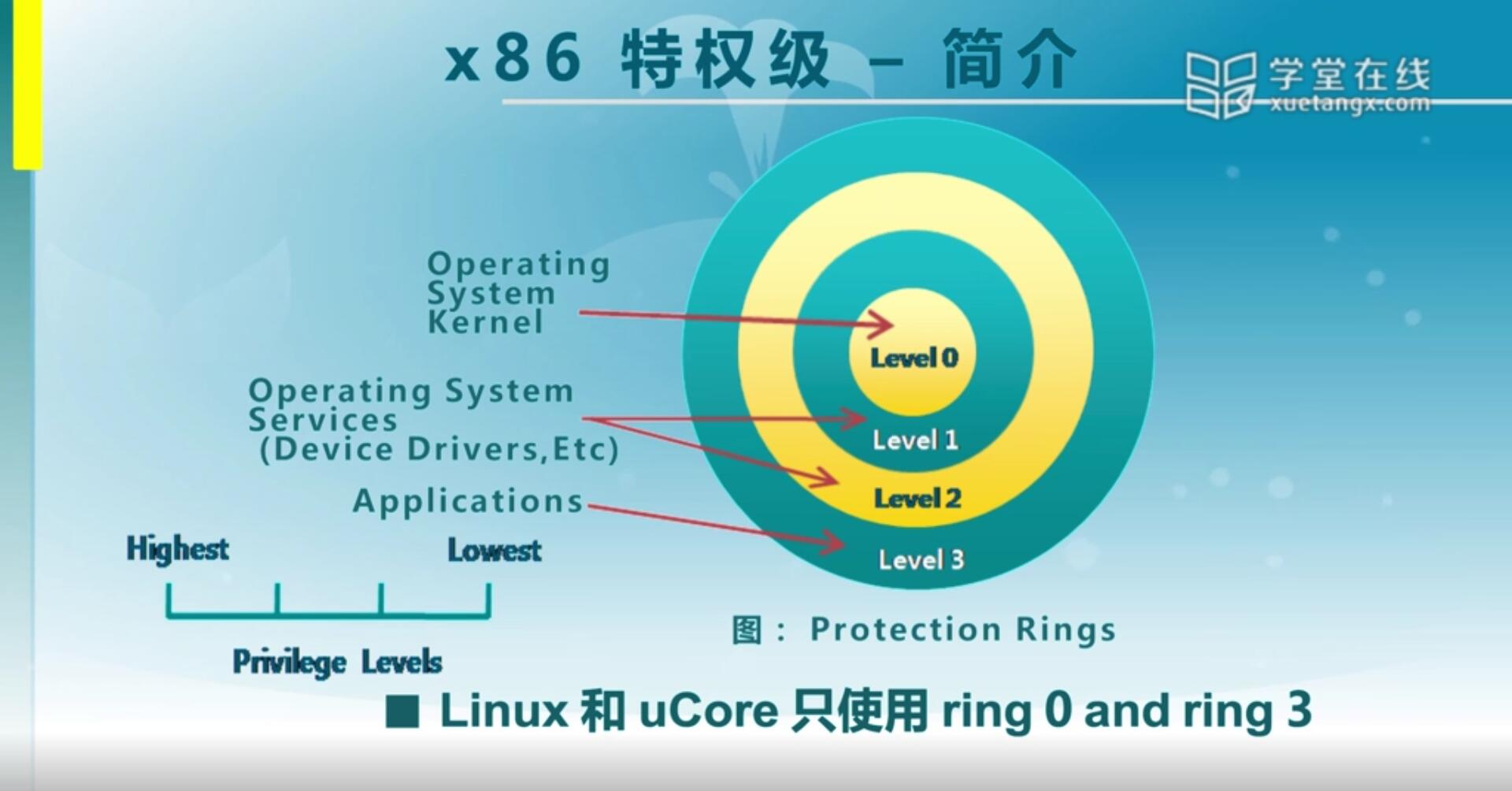
X86特权级有0,1,2,3四个特权级,数字越小特权级越高,其中内核是在level 0,应用程序一般是放在level 3。意味着应用程序无法去破坏内核里面的代码或者数据,但是它可以得到内核态提供的服务。同时我们还看到有level 1和level 2,当时intel设计CPU的时候考虑比较灵活,认为也许还有其他一些应用需要更多的层级来做区分,但其实在我们现在的操作系统设计一般来说,只需要两级,就是一个操作系统内核有一个级别,一个是应用程序有一个级别基本上就够了。对本次lab2实验来说,只需要level 0和level 3就够了。
那么有一些指令只能在ring0里面执行,这些指令是X86的特权指令,那这些指令一般也是由OS来完成的。那我们应用程序如果一开始在用户态的时候,如果它要去执行这些特权指令,比如说修改页表,响应中断,访问内核区域的数据的时候,还有访问中断服务例程去执行的时候,那就会产生异常,产生异常之后就会阻止它继续执行,这是一种典型的保护机制。那么它是靠OS做一个设置,在我们CPU硬件管理之下来确保一般应用程序处在ring3特权级情况下,它无法去访问ring0下面可以使用的一些特权指令和对应的数据等等。
1.2 x86特权级 - 段选择子
CPU具体是怎么检查特权级的?接下来我们会来介绍包括选择子以及后面的描述符,怎么结合在一起来完成这一条指令执行的特权级检查。
我们首先来介绍第一个概念:段选择子(Segment Selector)。
段选择子是位于段寄存器里的,那么我们可以说一个段有代码段,有数据段,也意味着你的代码在代码段里执行,你的数据位于数据段空间中。那么一条指令执行它就会去访问代码段和数据段。而这个RPL和后续会讲到的CPL它其实就是一个位于数据段,一个位于代码段,合在一起再和我们段描述符里面所对应的DPL进行比较。有点复杂,没关系,我们接下来逐步来看一下是怎么回事。
首先我们来详细看一下段选择子,我们可以看到DPL是位于段描述符里面的。段描述符是用来表示一个段的特征的一个很重要的数据信息。我们这里面关注的和特权级相关的是DPL,就是跟这个段所相关的一个特权级。一条指令要访问一个段,那这个代表了这一个段它特权级是什么样的,也意味着前面讲的RPL和这里面的DPL做一个比较,看这个特权级是否符合。
1.3 x86特权级 - 门描述符
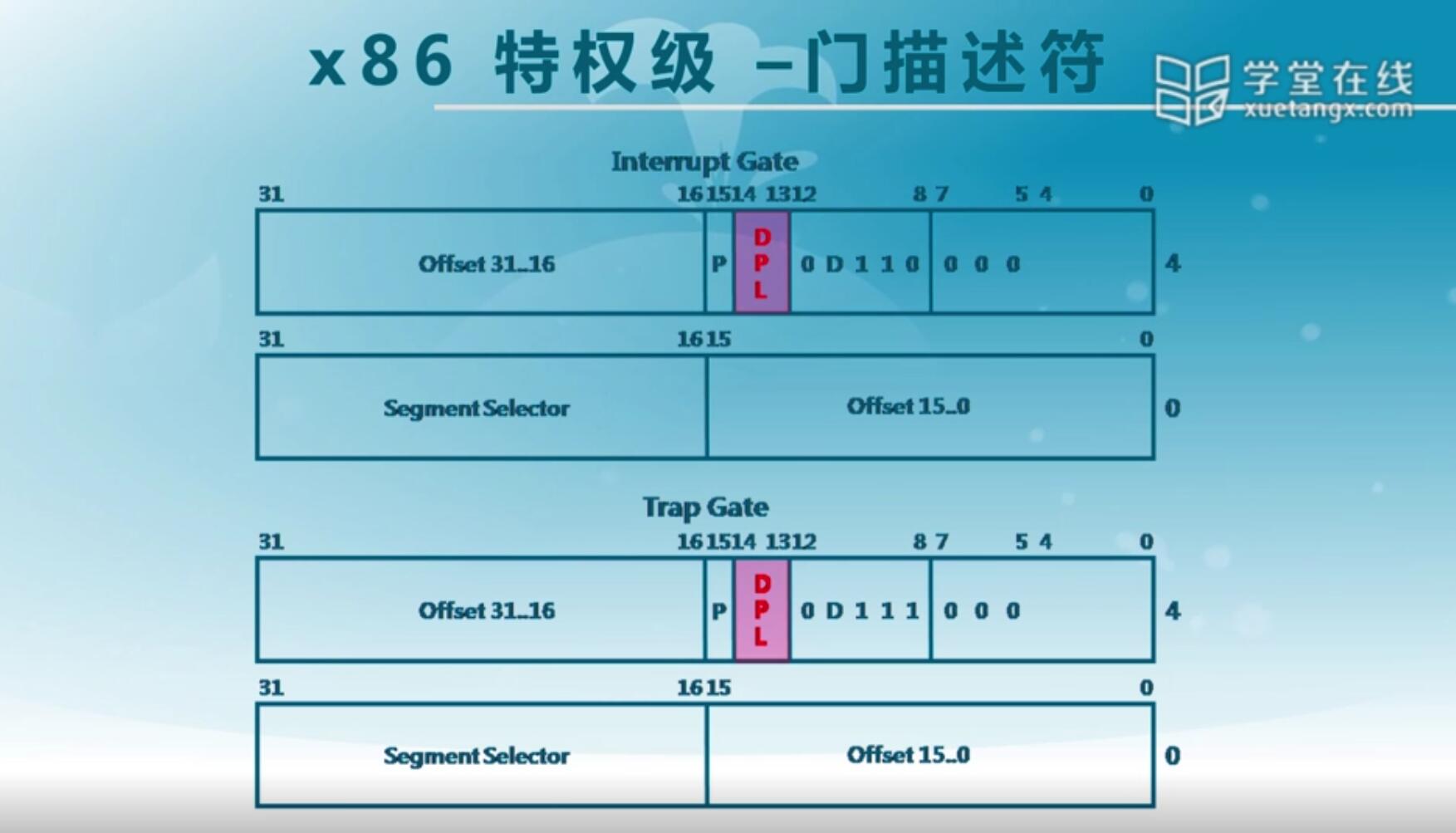
中断,异常,陷入呢其实都还是需要通过一定的特权级检查,所以在中断门,陷入门里它都有对应的DPL,这也是用来表明它们的特权级。
1.4 x86特权级 - 特权转移
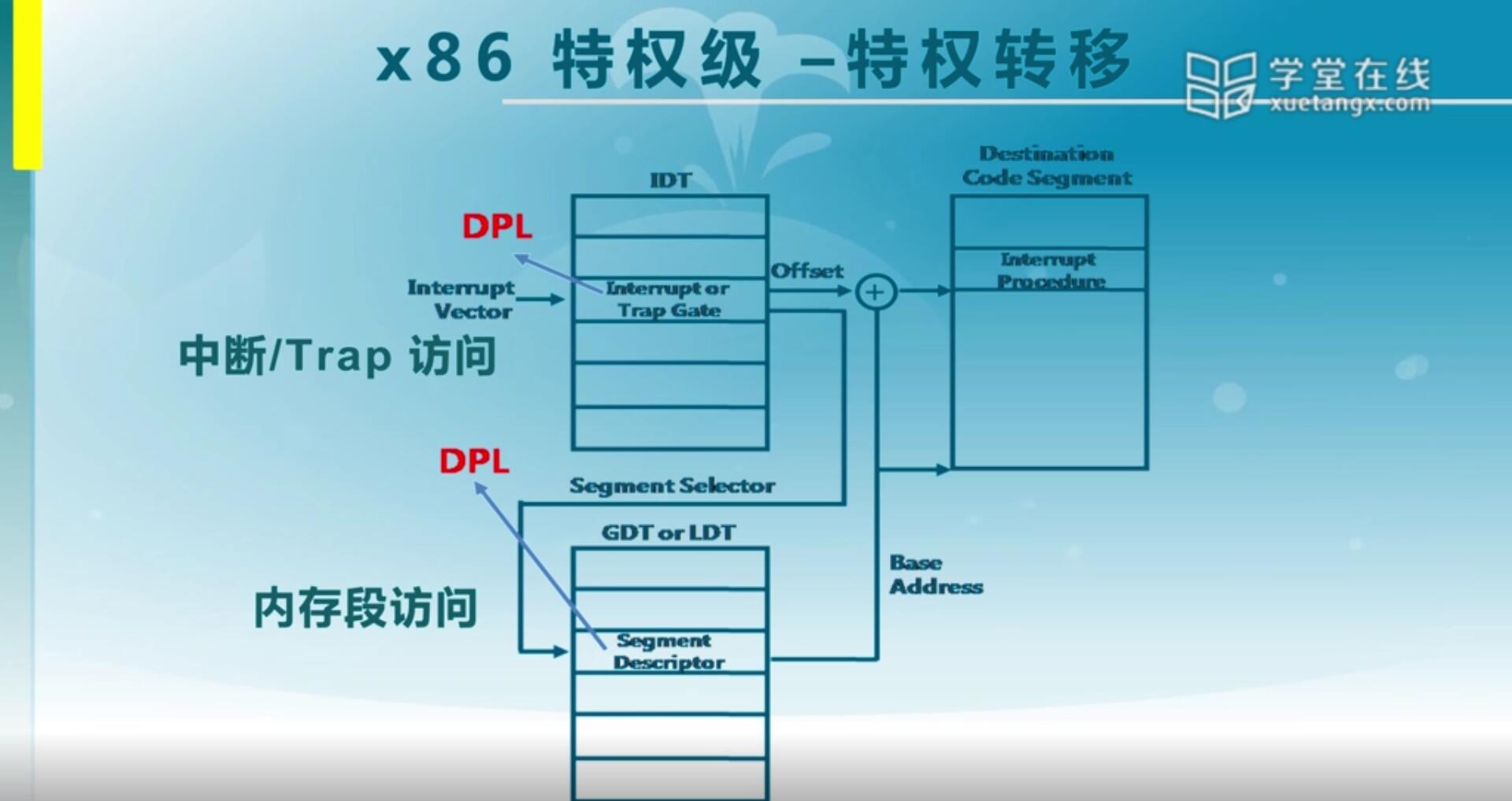
前面我们已经讲到了有段描述符,中断门和陷入门,它们都有对应的DPL。那我们在产生中断,或者完成一次内存访问的时候都会有对应的CPL和RPL。那么这个DPL,CPL和RPL之间都有一个对应的特权级检查,从而可以知道当前这个操作是否会产生特权级错误。
接下来我们看看怎么来比较:
RPL是处于数据段,比如说我们的DS,ES,FS,GS。那么它这里面是存了一个RPL,是当前你要访问的数据段对应的特权级。第二个,和指令的代码段特权级有关的是CPL。
一个指令要访问一个数据段的时候,它有两个特权级的表示,一个是当前特权级CPL,位于CS最低两位。第二个是对应的要访问的数据段的RPL,也是处于对应的段寄存器(DS,ES等),它那个低两位有RPL。它们都占了两个bit,和x86的四级特权级是一一对应的,那就是0到3。
另一方面,我们说你要访问的那个段,无论是通过中断访问代码段,还是通过内存访问来访问数据段,它都会有那个段的描述。无论是段还是门它都有一个DPL,这个DPL代表了访问目标的特权级。
RPL,CPL和DPL处于什么关系的时候这个访问是合法的?其实这个检查挺简单的,有两种情况:
第一种是针对中断,陷入,异常,这种情况称之为门情况。访问门的时候,它需要做两个判断。它当前的代码段CPL要小于门所处于的DPL,也意味着这个门的特权级要比较低,而代码段的特权级要比较高,这样才允许通过门。另一个要求CPL大于等于DPL[段],这什么意思呢?通过门之后目的是什么呢?是要我们去访问特权级更高的段,那么有了这个约束之后,其实就可以实现我们的一般的应用程序可以访问处于内核态的操作系统提供的服务,就是从低优先级可以访问高优先级的代码,这是说通过中断门可以完成这样的功能。
第二个是关于访问段的一个表述。那么对于访问段而言也一样,我们的代码段和我们要访问的这个数据段的请求一定要小于等于DPL[段]。那么这意味着什么呢?就是当前处于代码段执行这条指令,它发出请求,我当前处于这种状态,我要去访问某一个数据段,那么我本身的特权级要高于对应的目标,我们作为使用方,特权级要比较高才能访问,对应的数值比较就是CPL和RPL最大的一个值,即最低的权限要高于它所对应的目标段的特权级。
那么有了以上两个表示之后呢,如果说能通过检查,那么指令可以正常去访问,如果通不过就会产生所谓的保护错,也就是一种异常。
网络摘抄:
CPL是当前进程的权限级别(Current Privilege Level),是当前正在执行的代码所在的段的特权级,存在于cs寄存器的低两位。
RPL说明的是进程对段访问的请求权限(Request Privilege Level),是对于段选择子而言的,每个段选择子有自己的RPL,它说明的是进程对段访问的请求权限,有点像函数参数。而且RPL对每个段来说不是固定的,两次访问同一段时的RPL可以不同。RPL可能会削弱CPL的作用,例如当前CPL=0的进程要访问一个数据段,它把段选择符中的RPL设为3,这样虽然它对该段仍然只有特权为3的访问权限。
DPL存储在段描述符中,规定访问该段的权限级别(Descriptor Privilege Level),每个段的DPL固定。
(来源:https://blog.csdn.net/qq_43470425/article/details/112194881)
2. 了解特权级切换过程
2.1 x86特权级 - 通过中断切换特权级
既然ring3的应用程序无法有效地去访问ring0里的数据的话,那我们怎么去实现我们前面说的一个很重要的一个因素呢?就是我们的OS要给我们应用程序提供服务,那既然它都不能访问了要怎么提供服务呢?其实我们还是需要有一种手段,来实现不同特权级的一个跳转。比如说应用程序选择了内核的访问,通过一种机制让我们的控制流从应用程序跳到内核态去执行,这是怎么来实现的呢?在x86硬件架构里有多种实现方式,但是在这里面我们只用其中一种,就是基于中断,通过中断来实现特权级转换。
那么我们怎么通过中断来实现特权级切换?这里面有必要对中断做一定的讲解。其实中断它会有一个中断门,那么有了中断门之后呢,我们就可以通过中断描述符表建立好的这个中断门实现跳转。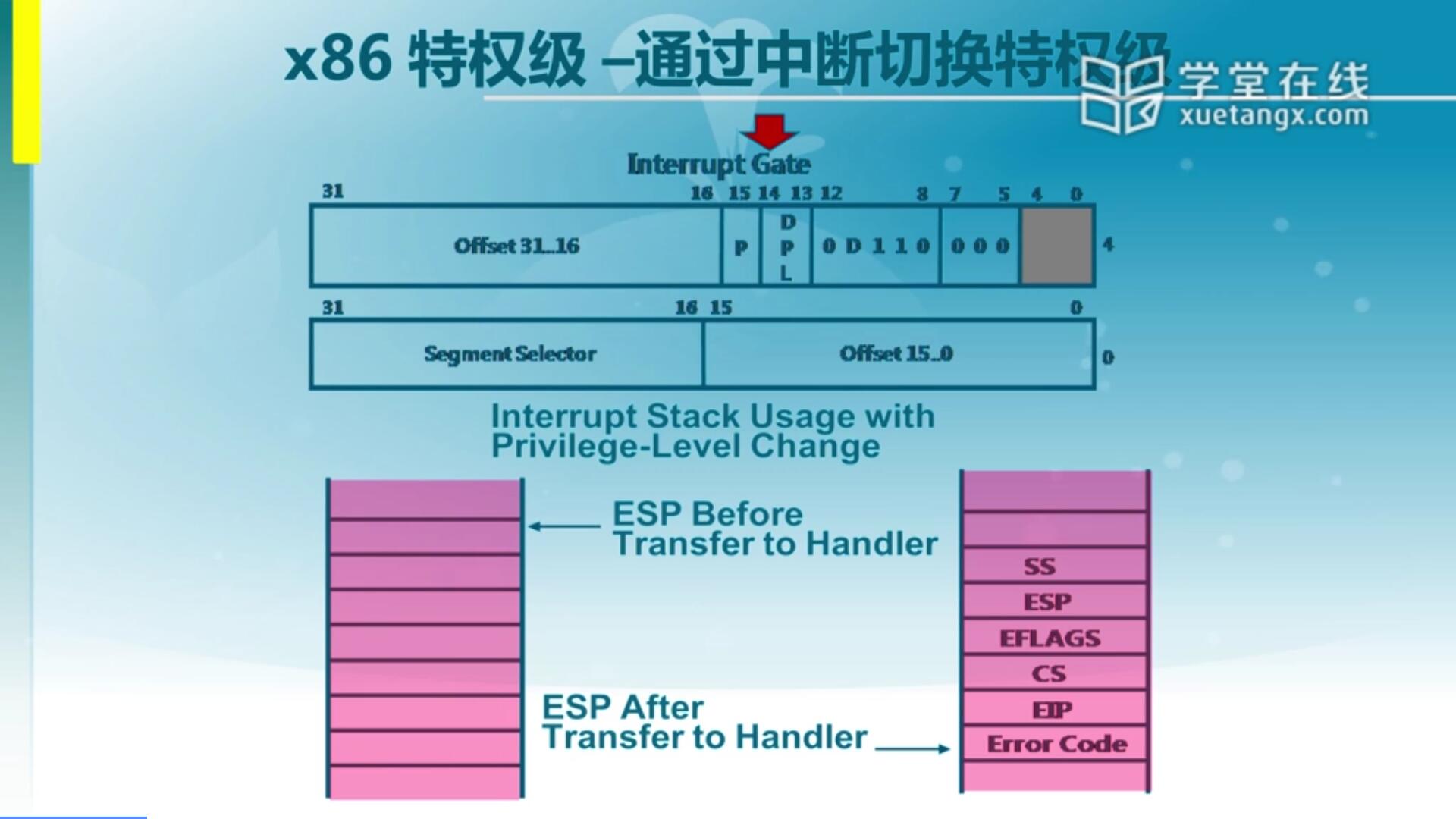
我们可以看到这里面中断的特权级的改变呢,首先我们可以看到正在执行的时候是在用这么一个栈在执行(Before)。然后如果说产生了中断,当中断产生之后会出现一个变化(After)。在我们内核态ring 0这个栈里面会压入一系列数据,以便于恢复被打断的程序继续执行。压入的数据上面的SS和ES代表的是被打断的程序的堆栈信息,EFLAGS代表的是被打断程序当前的标志位。还有就是返回地址CS和EIP,就是执行完毕中断服务例程之后还要回去继续执行,这是保存它要回去的地址。也可能还有一些是错误代码,这是跟异常相关的。
我们可以看到中断前后堆栈发生了变化,再次强调一下这个栈是属于内核态的栈。
2.2 x86特权级 - 切换特权级(0 to 3)
我们说产生中断后一定是会用到内核态的栈,那我们现在来考虑一下怎么能够从一个特权级切换到另一个特权级。
在开始完成lab1的时候,其实我们都一直在内核态里来执行代码。怎么实现一个内核态跳到用户态去让应用程序执行,那么这个就在于怎么去构造一个特殊的栈来完成工作,我们可以来看看:
这是我们说的内核栈,那么一旦产生一个中断之后呢,它其实会有一些压栈。那么这些压栈的信息要注意,因为我们当前是在内核态里执行,在ring 0里产生的中断还是ring 0,它的特权级没有发生变化,会把EFLAGS,CS,EIP和Error Code存进去。
现在我们希望它回到ring 3里面去,就是回到应用程序去执行。那么首先构造一个环境让它能回到ring 3。那我们就模仿了一个ring 3产生中断时的现场。跟同特权级的比起来,如果从ring 3跳到ring 0里面去之后它会多存一些信息,我们前面讲到了会存SS和ESP。而且SS里面的RPL是3需要注意,RPL是3也意味着SS用的是用户态数据段。同理在ring 0里面产生的中断它的CPL是0,代表了它当前运行在内核里面,这个时候我们希望它回去能跳到ring 3去执行,所以我们会把CPL改成3。改成3之后,也意味着如果把这个栈构造好了,我们最后通过一条特殊的指令IRET可以完成这个转换。一旦IRET指令执行之后,它就会把这些信息弹出内核态栈,来把这个内容恢复到对应寄存器里面去,包含了EIP,CS,EFLAGS,ESP和SS。那一旦把这些值赋给了寄存器之后呢,当前的环境就已经变成用户态了。因为它访问的数据,在SS这个访问数据,还有它访问的代码CS特权级都是3。所以说如果我们跳过去的应用程序想去访问处于内核态的一个数据的话会报错。这也意味着我们这时的SS和内核里的SS这个栈不是一个数据段的,而是不同的数据段,这实际上是一种特权级的转换。
我们可以看到发生转换之后,内核栈把信息弹出来了,同时需要注意一个新的栈已经形成(After Exit ISR),这个栈实际上是处于用户态的一个栈。它的SS和ESP已经变到这来了,而且它的代码也是变到CS和EIP指向代码。如果CS和EIP不做改变,那么它还是会到产生中断的下一条指令去执行。
2.3 x86特权级 - 切换特权级(3 to 0)
我们前面讲的是从ring 0到ring 3怎么完成,其实是通过构造一个能够返回到ring 3的一个栈,内核模拟一个ring 3中断的中断栈来完成的一个执行过程,最后通过IRET指令就可以完成寄存器数据的更新,从而实现特权级的转换。另外一点就是怎么从用户态跳到内核态去执行,这也是我们需要考虑的问题。实际上这种机制也是被Windows,Linux等通常的OS上的应用程序都采取这种方式,通过所谓的一个软中断或者叫trap来完成从用户态到内核态的转变。我们来看看基于x86架构怎么来完成从ring 3到ring 0的转变。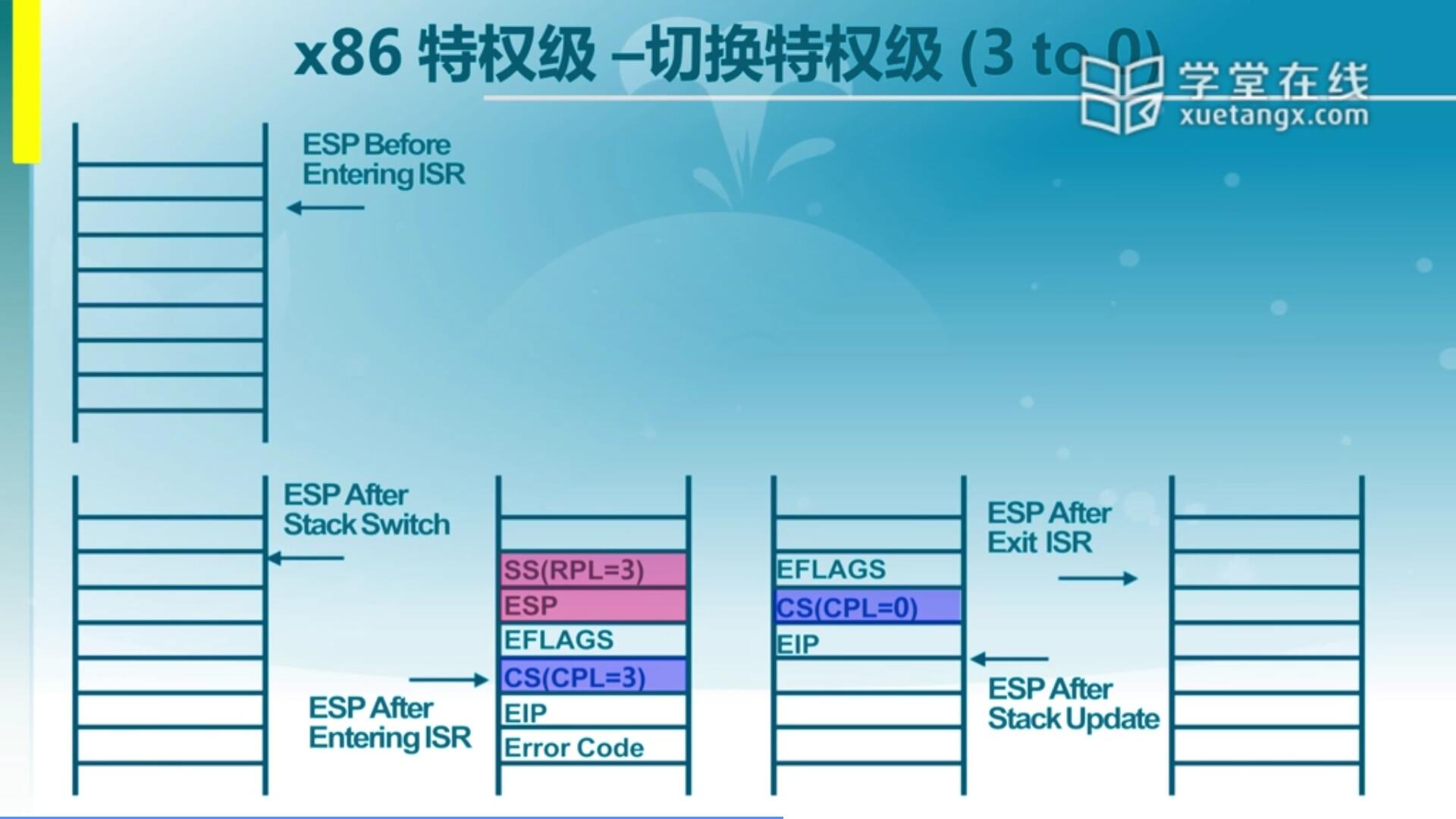
这是一个处于正在执行的一个程序的堆栈信息,那么一旦产生一个中断,那它实际上就已经实现了跳转。为了能够跳转,首先要把在IDT(中断描述符表)里把中断门建立好。中断门有一个中断描述符,它会指出来产生某一个中断之后,它会跳到哪去执行。但是在操作系统里面中断服务例程执行之前,我们的CPU一旦产生中断一定要保存一些信息,也就是之前说到的SS,ESP,EFLAGS,CS,EIP,Error Code。 当一个应用程序运行在用户态的时候产生了中断,那我们硬件会在处于ring 0态的栈储存这些信息,这些信息其实是被打断那一刻那个应用程序它的信息。这个信息有了,如果处理完这个中断服务例程之后,再执行IRET这条指令它就会根据这里面的信息再重新返回到ring 3里面去。那这时候我们不希望它返回到ring 3,我们希望它返回到ring 0怎么办?其实和我们刚才的方法是一样的,我们可以通过对这个堆栈的修改,使它执行完IRET指令之后可以继续留在内核态里执行。
我们做什么修改呢?首先需要注意SS和ESP不需要了,因为我们不需要回到用户态去。另外,我们会把CS做一个修改,指向内核态的那个代码段,还要把CPL设置为0。当然还要根据具体要访问到哪个地方去改变EIP,假设如果不改的话,这时候通过IRET指令让CPU把堆栈信息取出来,然后返回到EIP和CS指向的这个地址去执行,但需要注意这时依然是在ring 0里执行的。通过这种方式就可以实现从ring 3到ring 0的一个转变。
2.4 x86 特权级 - TSS格式
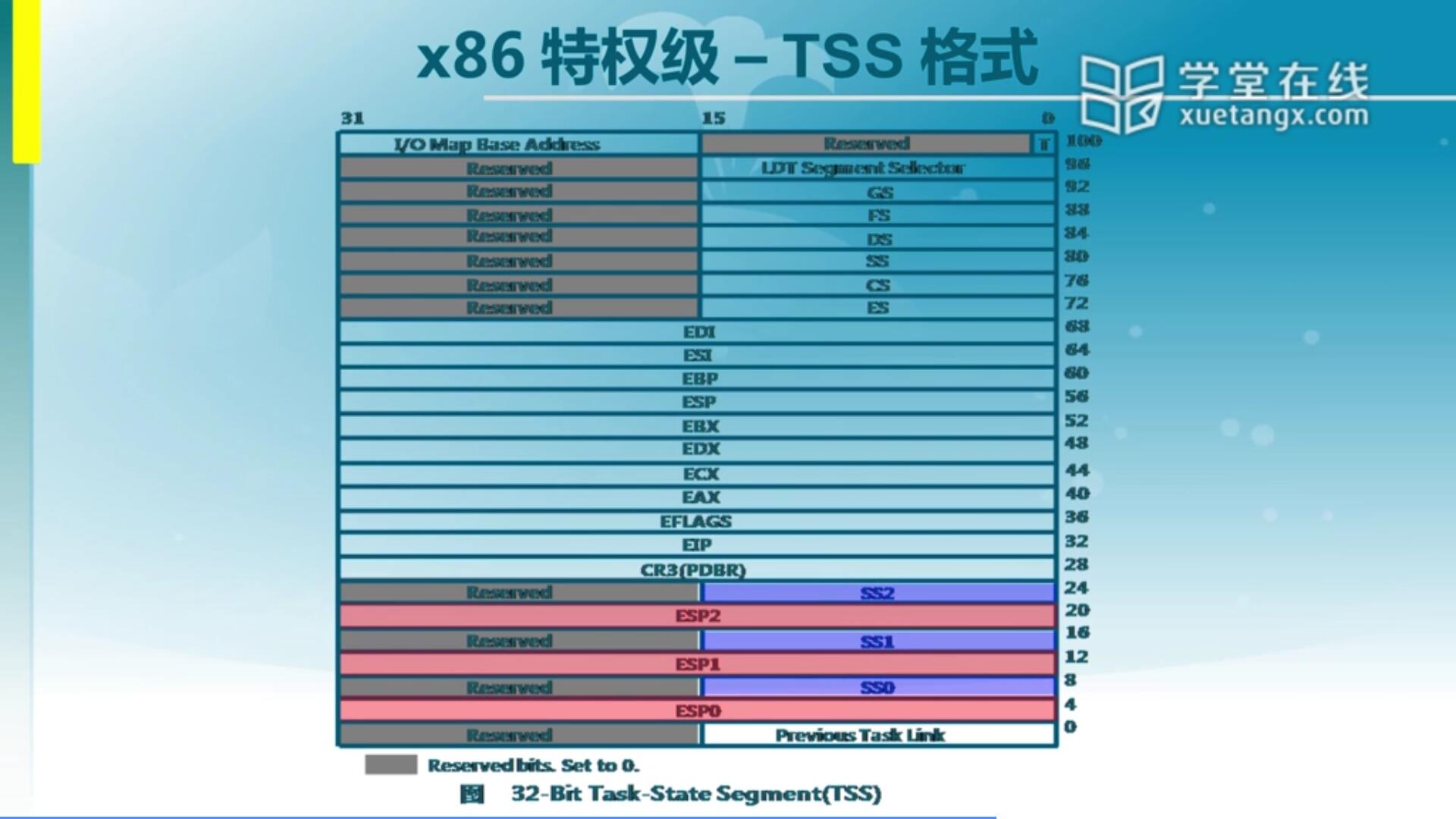
当一个应用程序通过某种手段,从一个特权级完成了到另一个特权级的转换之后,那到了另一个特权级它怎么知道那个特权级里的CS和SS位于什么地方呢?有同学说CS和EIP就表明他的地址,这个地址我们可以通过在IDT里建好了,当产生某一个中断该跳到什么地方去执行,这个地址可以搞定。但是另一方面呢,它这个堆栈SS应该在哪呢?那么这个信息其实在IDT里是没有呢,是在另一个我们称之为任务状态段(TSS),Task State Segment这么一个段保存了不同特权级所用道的很多寄存器里面的信息。比如我们说的SS,ESP等。虽然里面信息很全面,但其实我们关注的是不同特权级的堆栈信息,就是它的SS和ESP。那么可以看出来对于不同特权级的SS和ESP,这里面都有保存。我们可以看到里面保存了ESP0-2和SS0-2的信息,即ring 0到ring 2三个特权级里的堆栈信息。所以为什么说ring 3的应用程序产生了一个中断,或者说执行了一个软中断指令INT可以跳到内核里执行。它跳过来之后,CPU会根据TSS里面存的信息来设置新的堆栈,然后再根据IDT里的信息来设置新的地址。所以说一旦从一个特权级跳到另一个特权级,我们的地址会发生变化,我们的堆栈会发生变化,这个地址和堆栈都由不同的硬件机构来进行保存。我们OS也要去设置好TSS里面的内容。
2.5 特权级 - 栈切换中获取新的栈
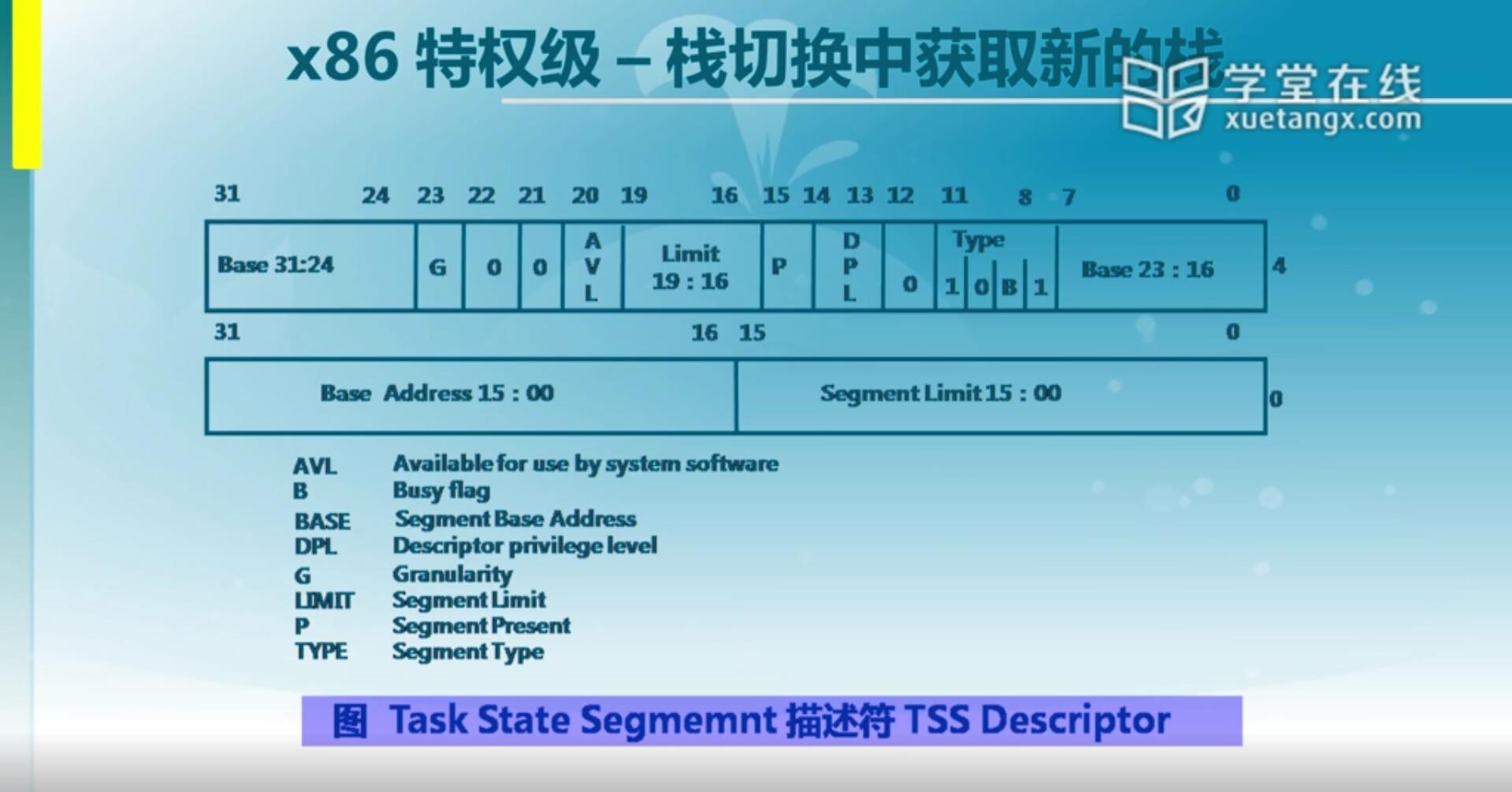
TSS它其实是一个特殊的段,这个段位于内存中,那它到底怎么访问得到呢?这里运用到我们以前讲到的GDT(全局描述符表),GDT里专门有一项来指向TSS,称之为有一个特定的TSS的一个描述符,放在我们GDT里面。在这个描述符里面很重要的一个是它保存了它的地址,就是TSS这个地址,那么根据这里面保存的地址我们可以找到TSS的内容。那么这就是说我们的CPU怎么能够去找到中断产生时要切换的特权级里面的堆栈信息,甚至还有其他信息,对于ucore而言我们用最简单的两个,就是它的堆栈信息SS和ESP。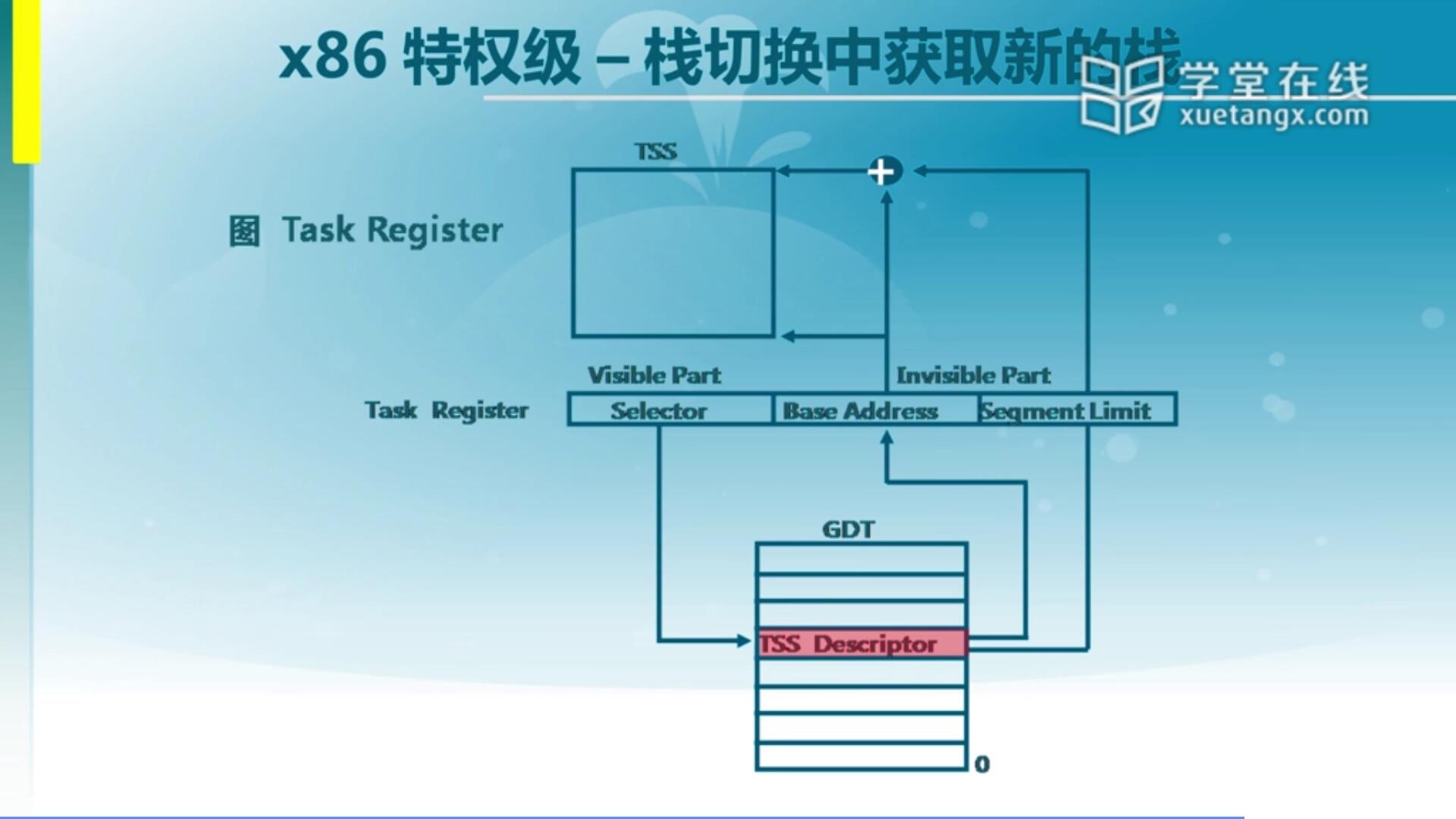
CPU这么去找,那里面的内容需要我们软件去写。跟前面介绍的一样,我们的软件会去填写GDT,IDT,同样我们的软件会把TSS里的内容给填好。填好TSS这个段里的内容之后,我们需要让CPU知道这个段位于什么地方,以便于后续一旦产生切换之后去哪里找这个信息,那首先需要知道TSS这个段的基址。这个段的基址在哪保存呢?我们前面已经讲到了,在全局描述符表里面你要去填写一项TSS的描述符,它会指向TSS的相应内容,但是也需要注意这里面保存的信息也是内存里的单元,所以说我们的硬件还有一个优化,它有一个TSS Register(寄存器)来缓存这个TSS里面的内容,从而使得每次CPU要访问TSS的时候,它要去根据这个寄存器的内容直接找到相应的位置,这个寄存器是个特殊寄存器。那我们会在完成对TSS的初始化之后,通过这个寄存器来加载它的基址。这两步都可以有效找到我们的TSS。
那我们前面讲的大致是对硬件的介绍,其实在ucore里也对此有一些相应的初始化工作都涉及在分配一个TSS memory,实际上分配一块内存,要在这个内存把它作为一个TSS的空间,再做初始化,特别要设置对我们的SS0和ESP0。再进一步会在GDT里填写TSS描述符,最后还要设置TSS selector,这是Task Register相应的设置工作。
3. 了解段/页表
接下来我们看一下X86内存管理单元MMU。
3.1 X86 MMU - 段机制概述
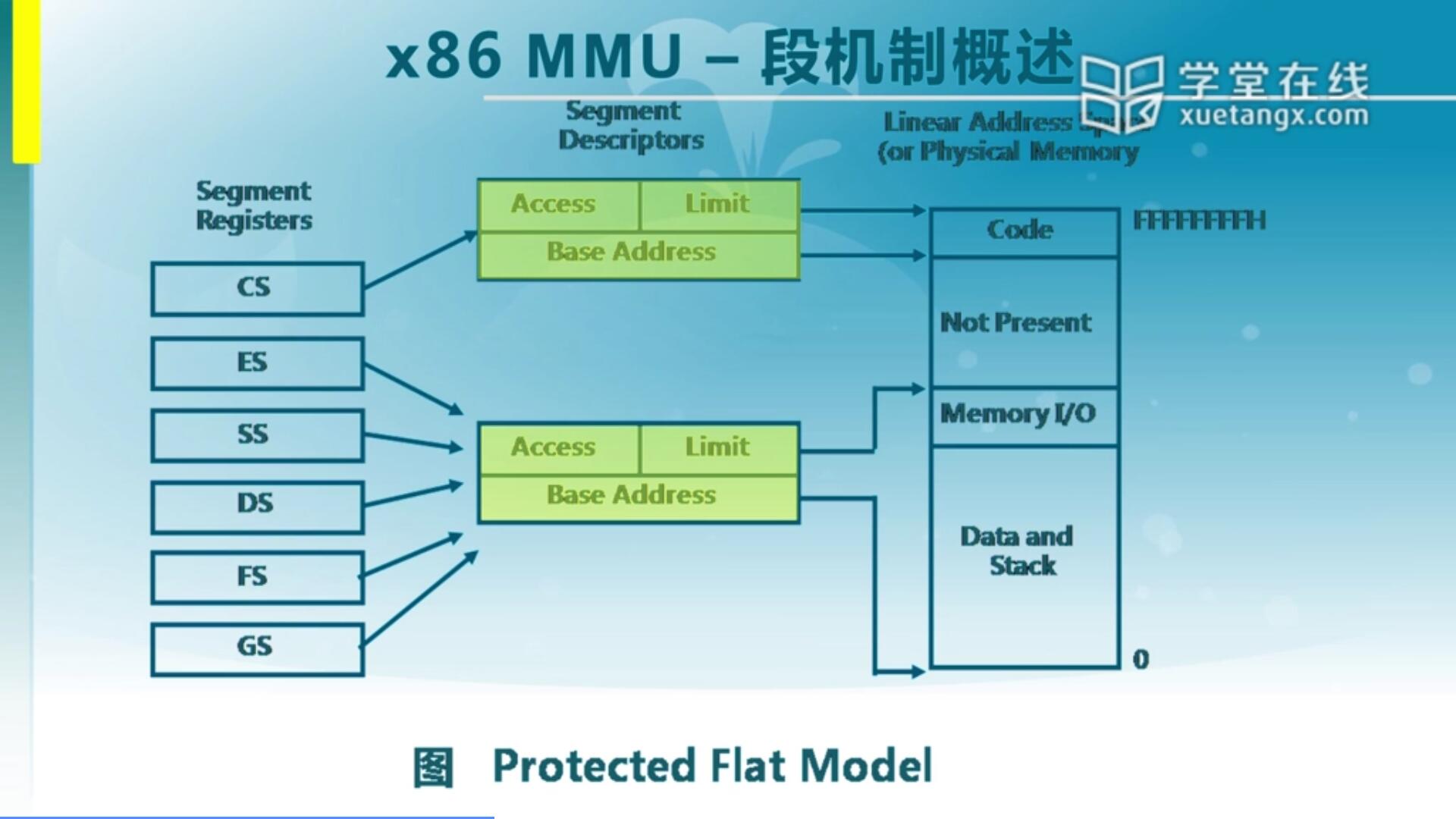
首先我们看一下这个段机制,我们可以看到在X86 MMU里面它首先是有一套段机制,这个段机制包含了比较多的一些功能的一些部件。第一个是有一系列的寄存器,第二个有段描述符,那么寄存器里面它最高端是十几位是专门用来作为一个index,作为一个索引来找到全局描述符表里面的一个项。全局描述符表GDT可以理解为一个大数组,根据数组找到对应的数组项,一项就是一个所谓的段描述符,在段描述符里面表明了你要访问的那个地址对应的映射关系。这里面有一个Base Address是最主要的,有了这个基址之后再加上EIP作为Offset合在一起形成最终的线性地址,如果没有启动页机制的话,线性地址就等同于物理地址,从而可以完成前面由我们CS加EIP所形成的虚拟地址到线性地址的一个转换。左边是虚拟地址表示,右边是最终的物理地址或者说线性地址,它中间通过段机制的段描述符来完成映射关系。段描述符里面重点是基址(Base Address)和限址(Limit),这两块信息很重要,我们有这两块信息之后就能知道怎么完成转换。那其实可以看出来这些信息,是需要这些段描述信息,还有寄存器里的Index都需要我们的软件提前设置好,这个软件是谁呢?很明显就是我们的OS。
3.2 x86 MMU - 段选择子中的隐藏部分
那可能会有同学会提出质疑,GDT它到底是放在内存里面还是CPU里面的呢?其实GDT是放在内存里的,为什么?因为GDT它比较大,如果放在CPU里对CPU压力比较大,所以说既然放在内存里面,每次地址映射时都要去查GDT,简单我们也可以称之为段表。访问这个段表那其实开销很大,我为了访问一个地址单元,我要再去访问这个地址,内存的速度远远小于CPU的速度。
那我们有什么办法来加快这个选择的速度呢?这其实是由硬件来完成,我们的硬件会把OS建立在GDT里的段描述符的信息给放在一个特殊的位置,隐藏的部分。这隐藏的部分就是我们几个寄存器(CS,SS,DS,ES,FS,GS)。它这里面有一部分看得见是16个bit,段寄存器的值,但是还有一个大段是看不见的,是隐藏在后端被硬件直接控制。它里面缓存了我们的基址,还有限制等等其他一些信息,这里面只关注两个:基址和段大小(limit)。那么这个信息是放哪儿呢?是放在CPU里的,所以它可以通过CPU内部的一个访问(就是我们说的MMU)来加快整个段的一个映射过程,从而会提高效率。
(要在保护模式下获取物理地址,需要执行以下步骤:
(每个段寄存器都有一个“可见”部分和一个“隐藏”部分。可见部分就是上面的段选择子 ,(隐藏部分称为”段描述符缓冲器”)当将段选择子加载到段寄存器的可见部分时,处理器还将使用 段选择器指向的段描述符的基址、段限制和访问控制信息。 这部分内容程序不能访问,由处理器自动使用。
所以段寄存器中保存的不在是段地址,而是段选择子,真正的段地址位于段寄存器的描述符高速缓冲中。
CSDN摘抄:
https://blog.csdn.net/qq_22654551/article/details/106743267 )
3.3 x86 MMU - 建立GDT tables(kernel init)
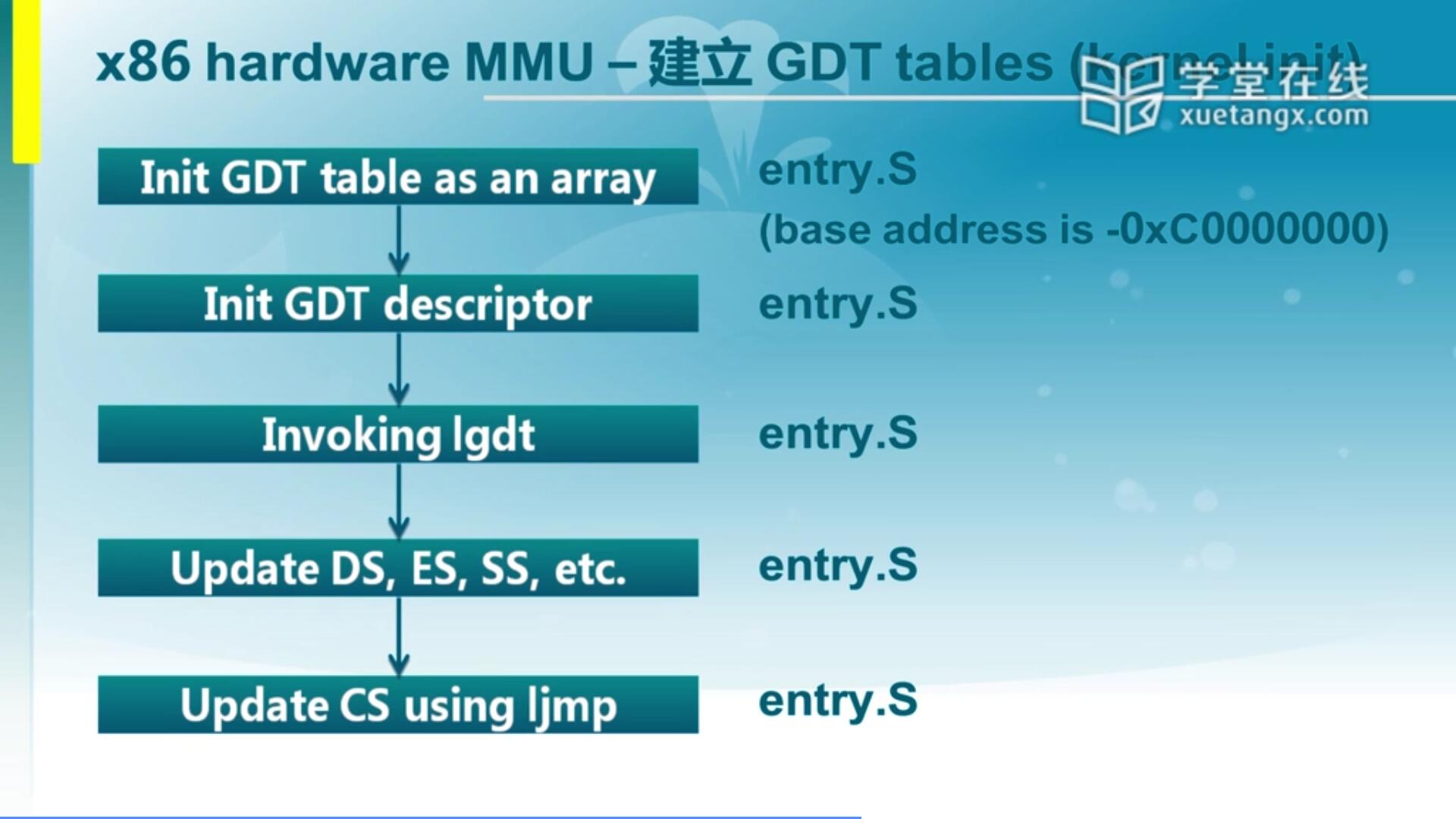
我们可以看到这里面说通过这些操作在entry.S里面,我们的Ucore会建立好这个映射机制。它完成了和我们前面讲的lab1所用到的bootloader的建立机制不太一样,为什么这么说呢?因为lab1建立的是对等映射,也就是说虚拟地址是0,物理地址也是0,他们是完全对等的。而在lab2和lab1会有很大区别,为什么这么说?因为link的时候,它用到的那个描述文件实际上指出了它的偏移是-0xC0000000,还是负的,为什么,这也是一个问题。那也意味着如果这么来设置的话,我们访问如果虚拟地址是0xC0000000的时候,实际上对应的线性地址是0,是这么一个映射关系。
3.4 x86 MMU - 建立 GDT tables(bootloader)

上面讲的是Ucore在一开始执行的时候,它建立的映射关系。我们再回顾一下lab1,在lab1里面bootloader也建立了一个映射关系,那个映射关系是一个对等映射,就是0地址对0地址,1000对1000。它的建立过程大致是类似的,只是唯一的不同在于映射关系。放在GDT里面的段描述符里面的信息(Base Address)是不一样的,这导致了它们的映射关系完全发生了变化。
3.5 x86 MMU - 建立GDT tables(使能页机制 enable paging)

我们希望OS能够用上页机制,那其实段是一种映射机制,页是另一种映射机制,这时候有个取舍,到底是两个都充分利用,还是强调一个而忽视或弱化另外一个映射机制呢?对于硬件来说,选择页机制相对来说有助于硬件机制对它进行有效的处理。所以说你可以看到当前主流CPU里面,除了x86之外还有MIPS,ARM,PowerPC等等,都采用了这种页机制为主的一种映射关系,所以在ucore里面也是一样。还需要通过段机制里面的安全保护手段来确保整个系统的安全,但是我们弱化了它的映射机制。怎么弱化呢?那既然说我们要选择页机制来完成这个映射,我们还是希望能够说把我们的段机制又恢复回去,恢复到前面说的对等映射。它的GDT建立过程还是一样的,改变的仅仅对全局描述符表里面的段描述符内容的改变。因为那个内容里面记录了每个段的基址,那个实际上是用来映射用的。
4. 了解UCORE建立段/页表
4.1 x86 MMU - 页机制概述
接下来我们来看怎么建立页的映射机制。为了能够理解这个机制,我们首先去了解一下X86 CPU里面怎么来完成基于页机制的一个地址映射的。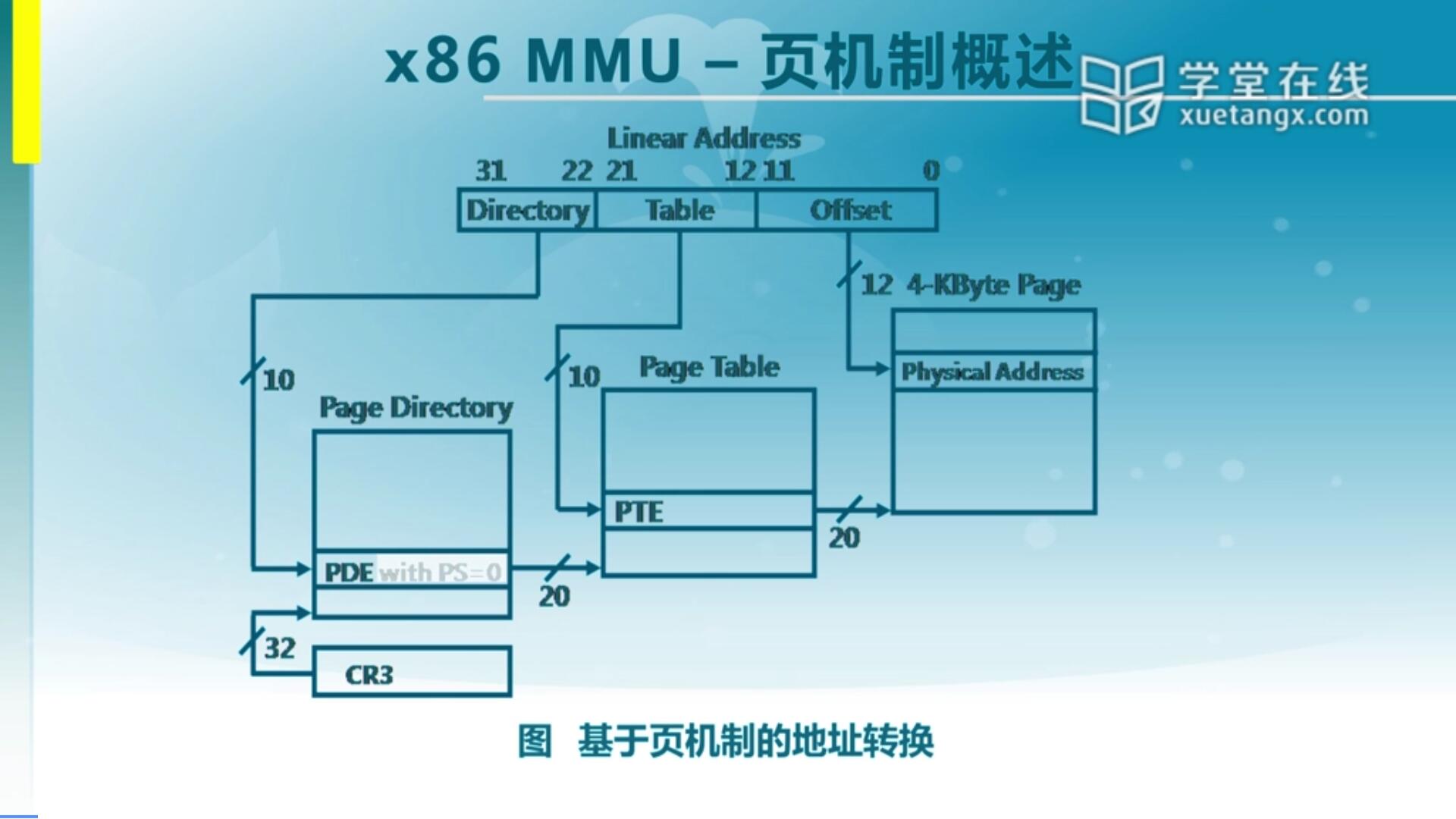
假定已经建好了一个页目录表(Page Directory)和页表(Page Table)。对于一个线性地址,它分了三部分,这实际上是一个典型的二级页表。最右边是一个Offset(页内偏移),占了12位。中间Table是二级页表的偏移,占了10位。地址最高位的部分Directory(页目录项)也占了10位。
Directory是用来作为index查找页目录或者说一级页表对应的项,这里叫PDE,就是页目录的entry。在PDE(Page Directory Entry)记录的是二级页表的起始地址,所以说根据PDE的信息可以找到Page Table的起始地址。
同时根据地址中间部分Table这里面的10位作为index来查Page Table(二级页表)对应的项,称之为PTE(Page Table Entry)。这个PTE里面存的是我们的线性地址所对应的一个页的起始地址。这个页的大小是多少呢?其实可以通过Offset的位数算出来,它是12位,那意味着一个页的大小是2^12 B即4K。最终PTE对应的Base Address加上Offset形成了我们要找的物理地址。这就是在x86里面完成的一个基于二级页表的一个地址映射关系。
那我们可以看出来硬件是这么来查找一个线性地址是怎么转换到物理地址的。为什么把它称为线性地址而不是虚地址?因为我们前面说到了进入保护模式后,段机制是一定存在的,即使对等映射存在,也不能说为此把段的映射关系给取消到,这是它必须存在的一个很重要的原因,也是为了上下兼容。那其实这个线性地址和我们应用程序的虚拟地址是一样的,因为它是一个对等映射。
4.2 x86 MMU - 页机制举例
我们既然知道了这么一个映射关系,我们来看一个实际的例子。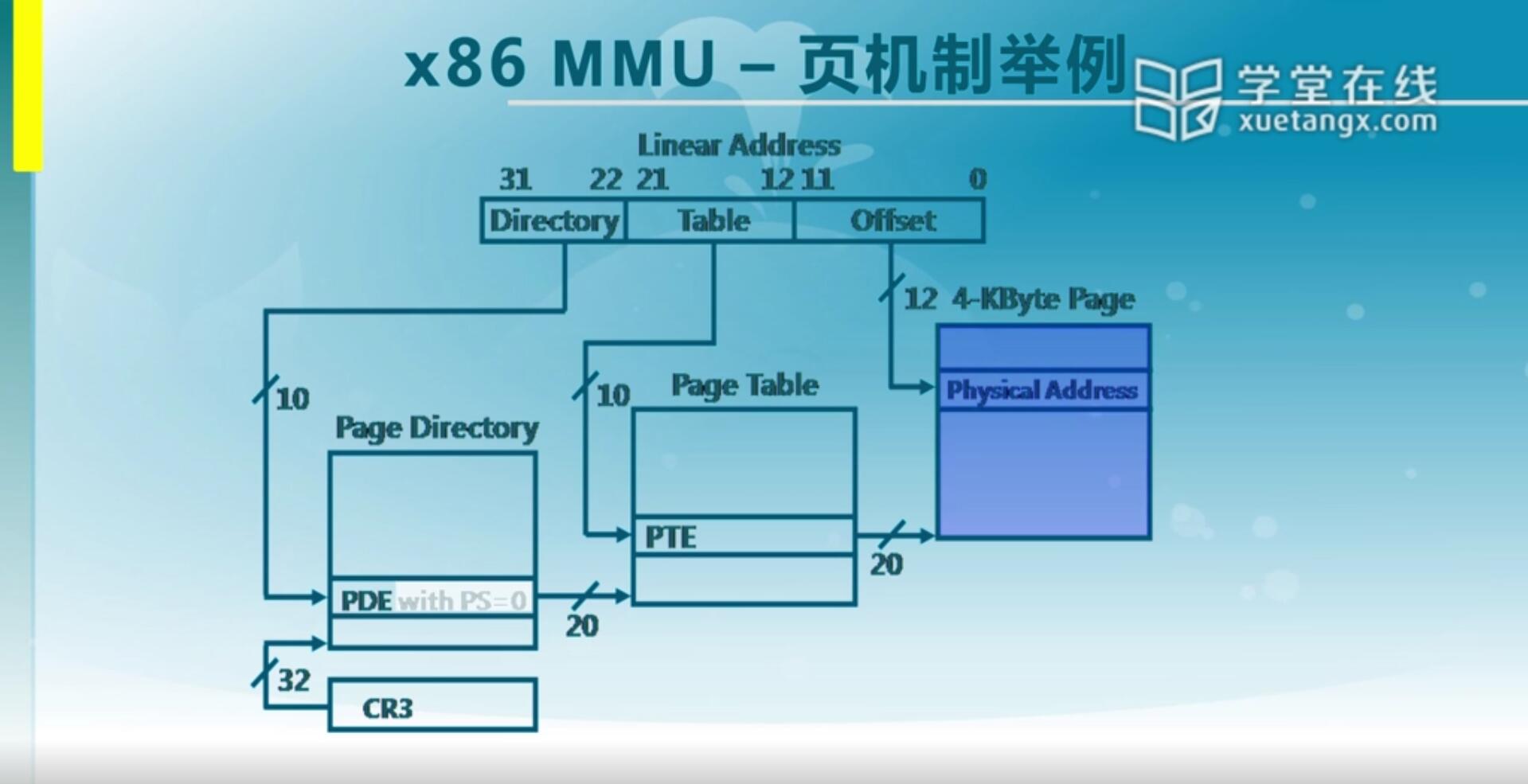
我们需要建好页目录表(一级页表),需要建好页表(二级页表)才能找到对应的页。那么页目录表和页表它其实也是4K大小,每一个PTE是32位的,那意味着4K可以存1024项。对于一个32位的虚拟的地址(0XC1234567),它实际上的物理地址是多少可以根据PDE,PTE算出来。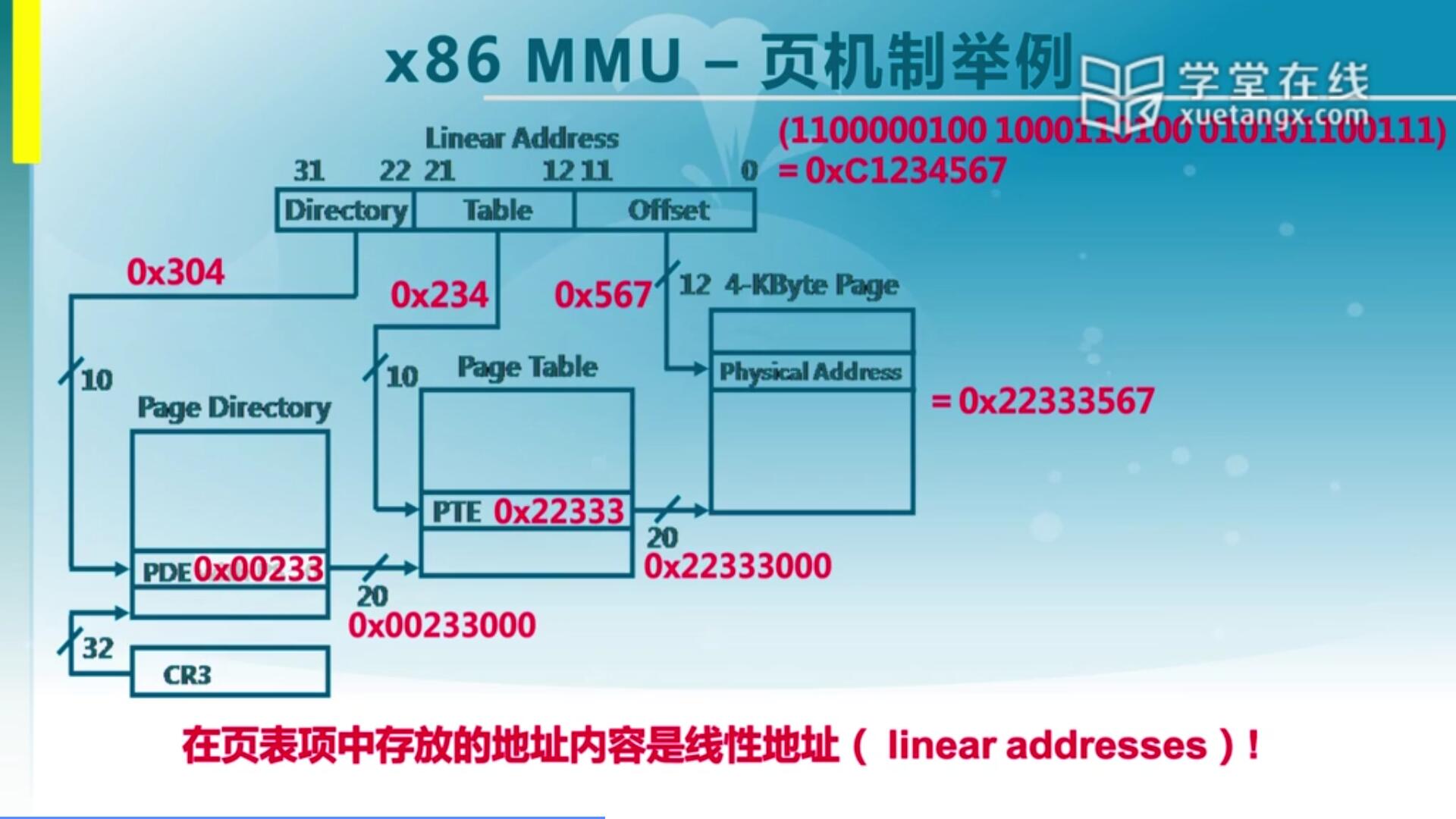
首先来看一下它的高10位,把它转16进制,仔细数一下发现它是0x304,那意味着我们需要查1024项里的第304项。第304项里面会存一个信息,这个信息比如是0x00233,这个0x233它是按照4K来做一个偏移,向右偏移了12位,所以我们再把它向左偏移12位。形成0x00233000这么一个地址。这个地址实际上是Page Table的一个物理地址的基址。找到这个Page Table之后,CPU会查中间10位,中间十位实际上对应的是0x234,234作为index找到PTE,PTE存的是0x22333。同样,它也是按照4K对齐,右移了12位,所以我们把它通过左移12位得到正确得所对应的物理页的基址,就是0x22333000。物理页的基址加上低12位的Offset(0x567),得到0x22333567,这就是它的物理地址。我们需要在lab2里完成这两级页表的建立,从而可以实现正确的对应关系。
另外还要提醒一下,在页表里存的是线性地址。还有一点是第一个页目录的起始地址存储在CR3寄存器,为什么只要一个CR3就够了呢?因为这是二级页表,4K的页目录表只有一个,所以只需要一个CR3就够了。
4.2 x86 MMU - 页表项
接下来我们可以看看对于页表或者页目录表里的一项它都包含了哪些关键信息。
这里面一个页表项是32位,我们这里面除了关注它的基址记录之外,还需要关注一些属性位。因为基址,就是存放的无论是物理页的基址还是页表的基址都是20位,还有剩下12位形成32位这么一项。那么那低12位存了什么呢?存的是将来访问页的一些属性,比如说这个页是否是只读的,用R/W位表示。这个页是内核态能访问的还是用户能访问的用U/S位表示,即user还是supervisor,就是属于一般用户访问的还是超级用户访问的,实际上就对应我们的用户态和内核态。那么其实和前面说的段的安全保护机制有异曲同工之妙,只是基于段的保护机制更加灵活,它可以表示可大可小的一块区域,它的特权级是ring0,1,2,3四级,而对于页表而言就两级,就是用户态和内核态,不过这也够了。还有其它一些位我们讲内存管理的时候会再逐步展开,它这些位可以有效的用来做内存的一些有效的管理。
4.3 x86 MMU - 使能页机制
使能页机制的方法和以前提到的使能保护机制是一样的,需要对一个特定的寄存器CR0的最高位PG(31位)置1。而以前我们说的使能保护机制则是最低位置1。
4.4 x86 MMU - 建立页表

我们的OS怎么来建立页表呢?比如说先分配页,Ucore已经有一套基于连续内存的内存分配的算法和机制,从而可以说我们分配一个4K的页来作为一个页目录的table。然后再把这个page给清掉,清掉是为了做初始化。之后除了页目录表之外,还要建立对应的页表,来对一个空间的内存建立对应关系,为此我们需要再页目录表和页表里面填好相应的项,那我们这里面建立的映射关系是什么呢?0xC0000000-0xF8000000这块空间会映射到物理地址的0x0000000-0x38000000。那这个其实可以看出来,它的偏移值就是0xC0000000,即虚地址比物理地址要多出来0xC0000000,实际上映射的是内核空间,使得内核态的代码和数据都是在0xC0000000这个之上的一个空间。那这个和我们在lab2的时候,会看到在编译,链接形成最后的Ucore代码的时候,它链接时候用到的起始地址就是0xC0000000。
同时我们又建立了一个奇怪的映射,就是0x00000000-0x00100000映射到0x00000000-0x00100000物理地址,这是一个对等映射。按道理来说我们建立好上面的映射就OK了,为什么还要建立这个对等映射且在enable了页机制之后,再次更新了GDT。为什么要更新GDT,是由于我们的页机制已经起作用了,页机制来完成从0XC0000000到0的映射,就是0xC0000000是虚地址,0是物理地址,这个映射靠页机制来完成了,那段机制来完成对等映射就OK。
那我们说更新GDT之后呢,就是让我们从段机制映射的关系从之前的不是对等映射变成对等映射,但变成对等映射之后它又做了一个取消操作,就是前面刚完成对等映射,最后又取消了对等映射,这个是页机制映射,有点多余的感觉?为什么?
4.5 x86 MMU - 在页表中建立页的映射关系
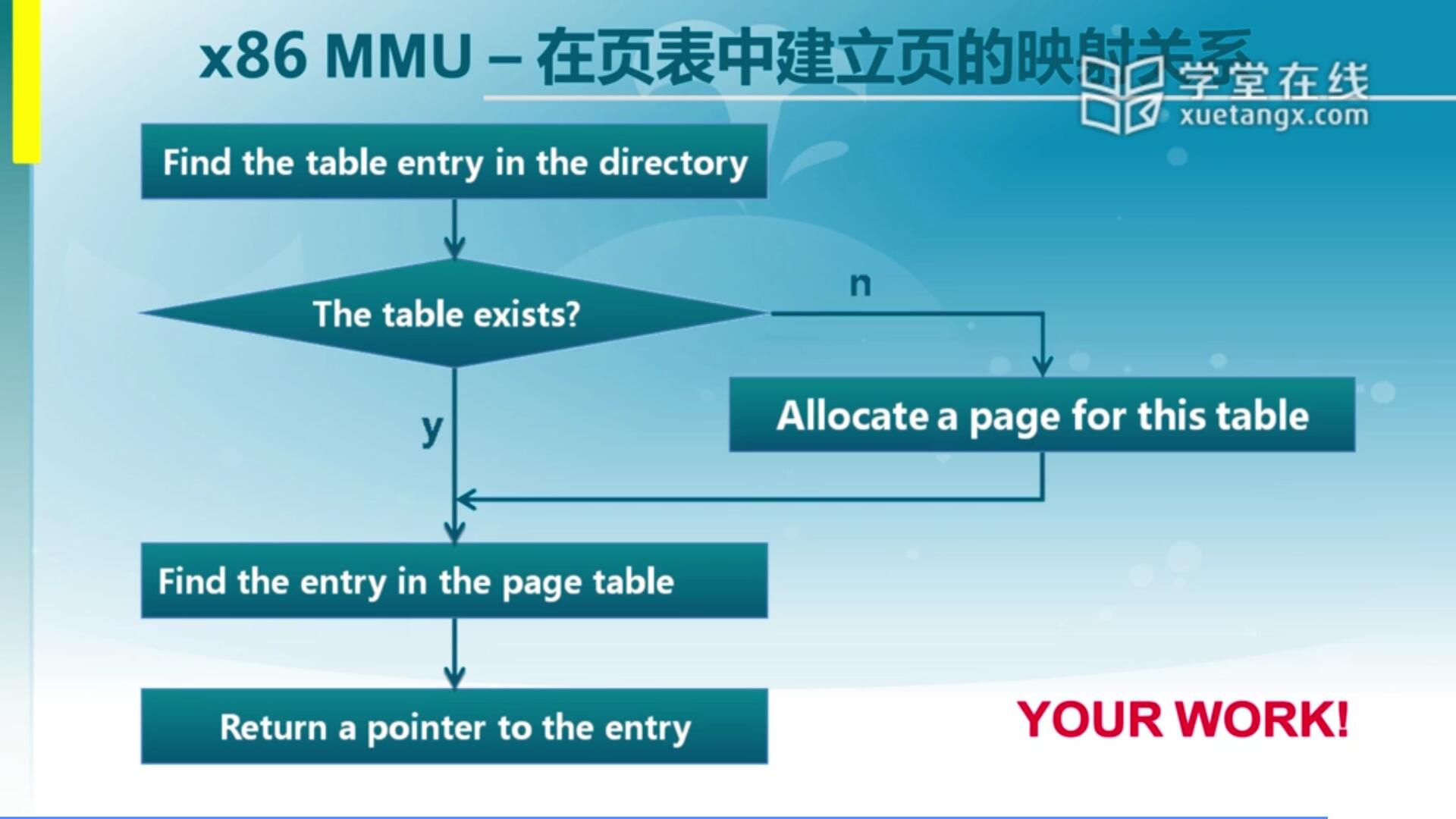
假设我们这个页表建立好了,接下来我们可能还要再完成一个特定的内存映射。这时候就可能需要去对PDE和PTE去做处理,如果我们的这个内存处于另一块空间,现在的页表没有对应到,所以说我们需要建立一个新的页表。这是一个作业,尝试着通过一个虚拟地址和物理地址,能不能分配一个对应的页表项,使得虚地址能够正确的映射到物理地址。这就是在页表里建立映射关系的这么一个练习,作为lab2的一个主要完成部分需要大家去完成。
4.6 MMU - 合并段机制+页机制
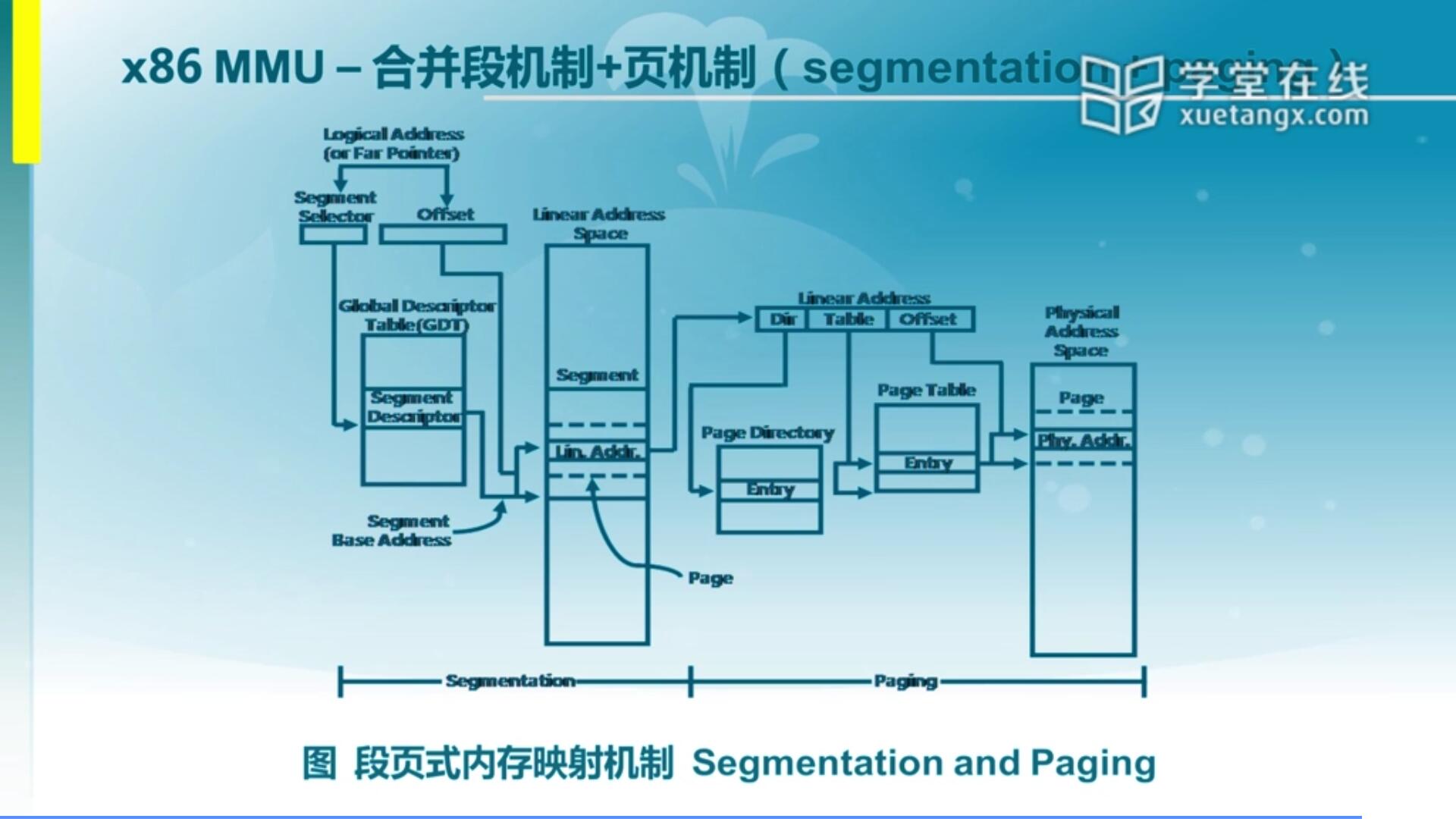
对于x86而言,它确实比较全面,既包含了段机制也包含了页机制。虽然我们这里面弱化了段机制的这个映射关系,但其实通过段和页的一个组合我们可以形成一个更灵活的组织方式。当然在现在的OS里面主要还是用页机制来完成了整个映射,段机制它的作用更多的体现在安全管理上,那其实在安全管理上面段和页也有一定重复,所以我们会根据具体应用情况来了解。
5. Lab部分
Lab2有三个基本练习,两个扩展练习,金毛做的是三个基本练习,来看一看它们三个各自的内容以及我完成的源码解析:
练习1:实现 first-fit 连续物理内存分配算法
在实现first fit 内存分配算法的回收函数时,要考虑地址连续的空闲块之间的合并操作。提示:在建立空闲页块链表时,需要按照空闲页块起始地址来排序,形成一个有序的链表。可能会修改default_pmm.c中的default_init,default_init_memmap,default_alloc_pages, default_free_pages等相关函数。请仔细查看和理解default_pmm.c中的注释。
下面用我完成的代码来介绍一下上面提到的四个函数的具体流程:
// 初始化空闲页块链表
static void default_init(void) {
list_init(&free_list);
nr_free = 0;
}
空闲页块链表是一个双向链表,我们用free_list做整个空闲页块的头节点,所以初始化空闲页块链表时首先对它进行初始化,list_init实际上是做了把free_list的前驱和后驱指针指向了自己这样一个操作。nr_free指的是可用的空闲页数量,初始化时设置为0。
ps:注意我说到页块的时候不是指一页,而是指一块连续的空闲页(但是英文注释说的一页可能是block)。
// 结构体Page
struct Page {
int ref; // page frame's reference counter
uint32_t flags; // array of flags that describe the status of the page frame
unsigned int property; // the num of free block, used in first fit pm manager
list_entry_t page_link; // free list link
};
// 初始化空闲页块空间
static void
default_init_memmap(struct Page *base, size_t n) {
//断言n>0,若不大于0则出现异常
assert(n > 0);
struct Page *p = base;
/* 给该空闲页块中的每一页进行标志位等信息的设置,
* 标志位(flags)中第1位设为1,
* 表示Page的成员property可用和自身是空闲状态,
* 之后Page的成员property设为0,
* property表示这个空闲块有多少页,
* Page的成员ref设为0,
* ref表示当前物理页被虚拟页面引用的次数 */
for (; p != base + n; p ++) {
assert(PageReserved(p));
p->flags = 0;
SetPageProperty(p);
p->property = 0;
set_page_ref(p, 0);
list_add_before(&free_list, &(p->page_link));
}
//设置该空闲页块中的第一页property
base->property = n;
//可用空闲页数更新,加上n
nr_free += n;
}
default_init_memmap是用来初始化一个空闲页块的空间的,具体怎么做我在代码中已经注释得很清晰了。再概括一下,接受两个参数,base是该块中的第一页,同时也用来做基址,n是该块的页数。我们循环n次,给该空闲块中的每一页进行一个初始化的设置(具体设置什么在注释中),设置完后把每一块往free_list的前面插入,free_list是头节点,实际上也就是每次加入到尾部。最后要把base的property设置为n,每一个空闲块只有第一页的property不是0,它记录了它这一块一共有多少空闲页。
// 将空闲页块分配出去
static struct Page *
default_alloc_pages(size_t n) {
assert(n > 0);
struct Page *page = NULL;
// 请求的页数n大于现有的空闲块总页数,无法分配
if (n > nr_free) {
return NULL;
}
list_entry_t *le = &free_list; // le初始化指向空闲页块链表头部
list_entry_t *le_ne; //le_next
/* 从链表头部开始遍历整个链表,直到找到比n大的一个空闲页块就分配出去 */
while ((le = list_next(le)) != &free_list) {
/* 使用le2page宏获取当前链表节点page_link所在的页,
* 关于le2page的实现技巧可以看实验0文章。*/
struct Page *p = le2page(le, page_link);
//当前空闲页块的空闲页数大于等于n,可以分配
if (p->property >= n) {
int i;
/* 把当前页块的前n个页的标志位进行修改,
* 将页标志位的第1位清零(ClearPageProperty),
* 将页标志位的第0位设为0(SetPageReserved),表示被分配,
* 将前后的链表断开,
* le = le_ne,即到之前保存的下一个节点继续做以上步骤 */
for(i=0; iproperty - n,即原数量减去被分配的数量 */
if(p->property > n){
(le2page(le,page_link))->property = p->property - n;
}
// 更新nr_free,page = p(被分配空闲块首页),返回page
nr_free -= n;
page = p;
return page;
}
}
//若在这里被return page,page = NULL
return page;
}
default_alloc_pages是将满足分配要求大小的空闲块给返回,若无法满足要求返回NULL。first-fit是最先分配,即空闲页块链表中遇到的第一块满足分配要求的会被分配走。具体流程上面的注释已经写得很清楚了,我就不再讲了。
// 将被释放的页块加入到空闲页块链表
// 2个参数分别为被释放页块的基址/第一页,页数。
static void
default_free_pages(struct Page *base, size_t n) {
//首先是两个断言,页数n>0和base是Reserved状态(被分配)
assert(n > 0);
assert(PageReserved(base));
struct Page *p = base;
list_entry_t *le = &free_list;
/* 首先使用while循环找到该空闲页块应该插入的位置,
* 空闲页块链表是按照地址从小到大排序的,
* 找到相邻地址的位置进行插入。*/
while((le = list_next(le))!= &free_list){
p = le2page(le,page_link);
/* 这里是p与base的地址相比较,如果大于base则找到了比base高的最近节点,
* 这时可以退出循环 */
if(p>base){
break;
}
}
/* 经过上面的循环,此时le所在的位置要么是比被释放空闲块基址高的最近空闲块,
* 要么是空闲页块链表头部,
* 所以在le前插入该空闲块是合适的位置,
* 之后进行相关标志位信息的修改(清零Rerserved,设置Property)*/
for(p=base;pflags = 0;
ClearPageReserved(p);
SetPageProperty(p);
list_add_before(le, &(p->page_link));
}
//给base专门设置ref和property
set_page_ref(base, 0);
base->property = n;
p = le2page(le,page_link);
//如果base+n == p,则说明最近的高地址空闲块是与base相邻的,可以合并
if(base + n == p){
/* 让base的property加上p的property,之后把p的property设为0,
* 因为p被合并到该空闲块中了 */
base->property += p -> property;
p -> property = 0;
}
//令le等于base的前驱节点,p = base的最近低地址页
le = list_prev(&(base->page_link));
p = le2page(le,page_link);
//如果此时le不是链表头且p的地址正好是base减去1个页大小,则p是相邻的,可以合并
if(le != &free_list && p == base-1){
//le向前遍历,直到找到相邻低地址空闲页块的首页
while(le != &free_list){
//合并相邻低地址,即p的property累加上base的property,之后把base的设0
if(p -> property > 0){
p -> property += base -> property;
base -> property = 0;
break;
}
le = list_prev(le);
p = le2page(le,page_link);
}
}
//可用空闲页数加上新的n页
nr_free += n;
return ;
}
default_free_pages是将被释放的页块加回空闲页块链表。空闲页块链表是按地址从小到大排序的,所以我们先从头开始遍历,给该页块找到合适的位置进行插入。这里是先找到比它地址高的第一个页,然后使用list_add_before在这个最近高地址页插入该空闲页块,之后判断它最近的高,低地址的页是否是相邻的,相邻即可合并成更大的空闲块。具体操作请看代码注释。
练习2:实现寻找虚拟地址对应的页表项
通过设置页表和对应的页表项,可建立虚拟内存地址和物理内存地址的对应关系。其中的get_pte函数是设置页表项环节中的一个重要步骤。此函数找到一个虚地址对应的二级页表项的内核虚地址,如果此二级页表项不存在,则分配一个包含此项的二级页表。本练习需要补全get_pte函数 in kern/mm/pmm.c,实现其功能。请仔细查看和理解get_pte函数中的注释。
下面先上代码再讲解:
// 获取二级页表项
/* 参数:pgdir:一级页表的基址,la:线性地址,
* create:若为1则在查不到二级页表项时创建一个二级页表 */
pte_t * get_pte(pde_t *pgdir, uintptr_t la, bool create) {
/* 首先根据一级页表基址加上用PDX宏取出线性地址la中的一级页号部分,
* 得到指向二级页表的一级页表项pdep */
pde_t *pdep = &pgdir[PDX(la)];
// pdep与PTE_P按位与,PTE_P为0x001,结果为页表项的存在位的值
if((*pdep & PTE_P) == 0){
struct Page* p;
//如果create=0或没有空间可以进行分配,则返回NULL
if(!create || (p = alloc_page()) == NULL){
return NULL;
}
//设置p的ref为1,即被虚拟页引用了一次
set_page_ref(p,1);
//取p的物理地址
uintptr_t pa = page2pa(p);
//给新页表初始化,所有字节全部设0,KADDR(pa)接收物理地址返回pa的内核虚拟地址
memset(KADDR(pa), 0, PGSIZE);
/* 一级页表项pdep的Present位,Writeable位,User can access位设为1,
* 即代表该页表项存在,可写入,用户态可访问 */
*pdep = pa | PTE_P | PTE_W | PTE_U ;
}
// 一级页表项PDE的基址加上la的二级页号找到二级页表项,并返回
return &((pte_t*)KADDR(PDE_ADDR(*pdep)))[PTX(la)];
}
get_pte通过三个参数:一级页表基址,线性地址,create(是否在查找不到时创建二级页表),来找到线性地址对应的二级页表项。基本每一步操作代码都有注释,这里就不再讲了。
练习3:释放某虚地址所在的页并取消对应二级页表项的映射
当释放一个包含某虚地址的物理内存页时,需要让对应此物理内存页的管理数据结构Page做相关的清除处理,使得此物理内存页成为空闲;另外还需把表示虚地址与物理地址对应关系的二级页表项清除。请仔细查看和理解page_remove_pte函数中的注释。为此,需要补全在 kern/mm/pmm.c中的page_remove_pte函数。
还是直接上代码,具体会在注释里说清楚:
// 取消二级页表项PTE的映射
// 参数:pgdir:一级页表基址,la:线性地址,ptep:二级页表项
static inline void
page_remove_pte(pde_t *pgdir, uintptr_t la, pte_t *ptep) {
// 结果为1则ptep存在位为1,ptep存在
if(*ptep & PTE_P){
//使用pte2page将ptep转为page
struct Page* p = pte2page(*ptep);
//page_ref_dec(p)把p的ref减去1,即被引用次数减1,若减1后为0则释放掉该页
if(page_ref_dec(p) == 0){
free_page(p);
}
//把ptep清零
*ptep = 0;
//最后别忘了把TLB中对应的页表项删除,调用tlb_invalidate即可
tlb_invalidate(pgdir,la);
}
}
page_remove_pte就是接受三个参数:一级页表基址,线性地址和要取消映射的二级页表项。整个过程大致就是先判断传入的ptep是否存在,存在则先将ptep所在的二级页表的ref减1,代表该页表被虚拟地址引用次数-1(因为背景是有一个虚拟地址在之前被释放了),若ref减1后为0则可以将该页表空间回收。之后将ptep也就是对应的二级页表项清零,最后把TLB(快表)中对应的页表项删除。
附一张完成lab后的ucore运行截图: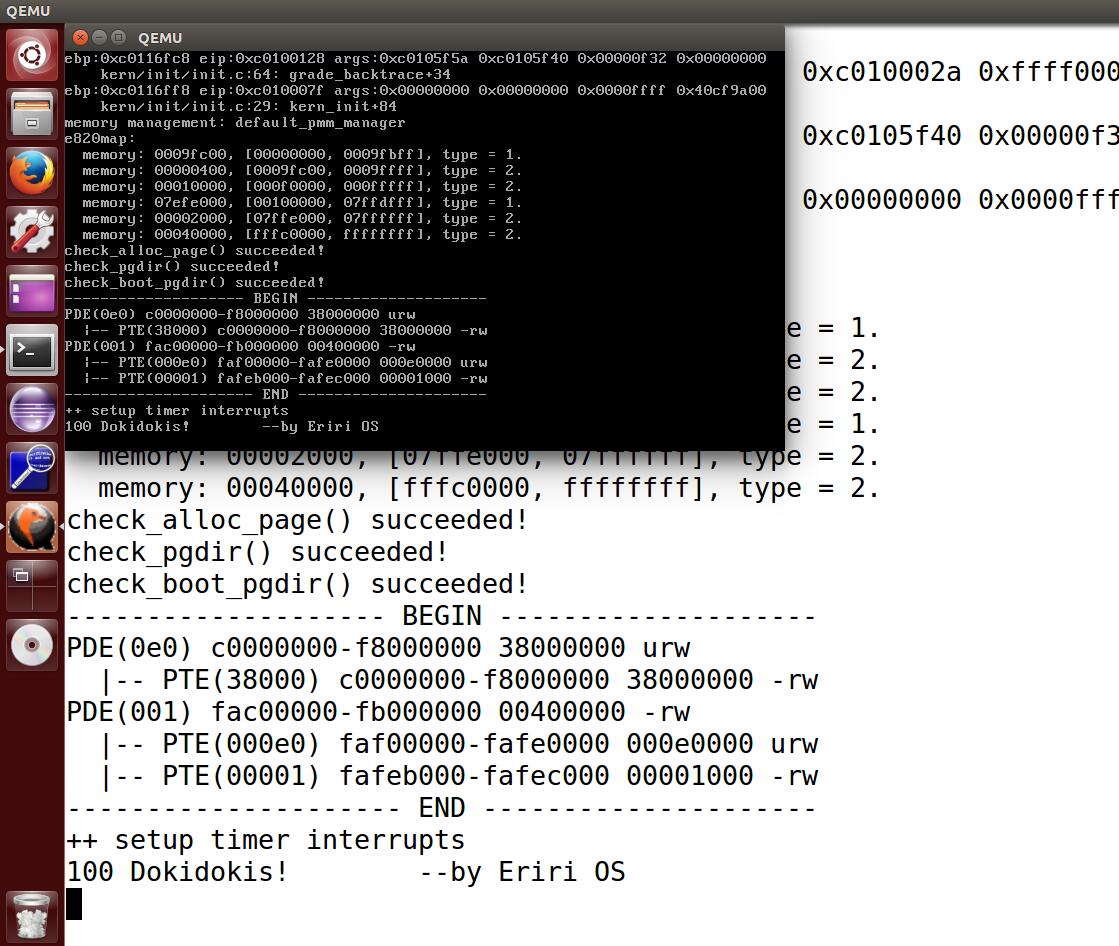
6. 杂谈
这篇lab2的文章写的是真的久鸭,三个作业也是做了一整天才做完的,OS这种高深的代码真的对菜鸡来说不好填啊!好不容易写完了,但是我还不能停下来放松!fight!哦!🍭🍭



