Mini-Tiktok !抖音精简版设计与实现!
1. 前言
Mini-Tiktok(精简版抖音)是出自字节跳动后端训练营的一个结营项目,虽然当时参加了但是最后临近期末,大家都没空所以没有完成。3 月份的时候为了找暑期实习,能给自己简历上写一份后端项目,我不得不一个人把它全部完成了😂😂。
这个项目吧,实现是比较容易实现的,在难度上自由发挥的空间很大,你可以只设计单体架构以及只使用 MySQL 作为存储,也可以设计微服务架构,使用 Redis + MySQL 负责存储,甚至加上消息队列进行异步处理和削峰,更难点还可以弄多个 docker 容器玩集群,并用 kubernetes 管理你的 docker 集群。嘻嘻,要不再考虑来个数据仓库分析用户数据呗?
因为我只有一个人,且时间比较赶的缘故,只是做了个适中的设计,是微服务架构,用上了 docker,但是没弄成什么 kubernetes 管理 docker 集群,这也导致我一直不敢投什么云原生开发(看起来像运维啊)。虽然是微服务架构,但是我拆分出来的服务并不多,有四个服务:用户服务(user),视频服务(video),鉴权服务(jwt),投稿转码服务(publish),接下来就来讲讲各服务的设计吧。
2. 数据库表设计
针对所有需要实现的功能设计了五张表,以下是它们的字段和索引:
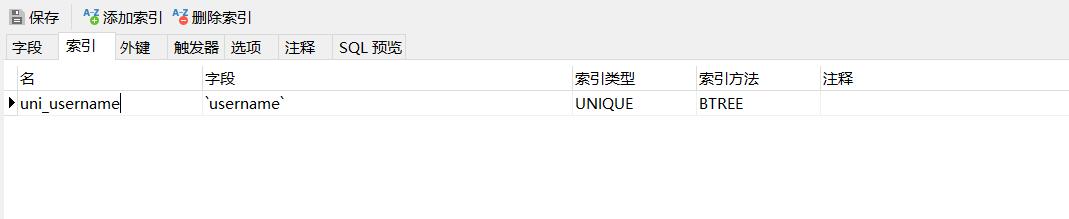
User 表字段:id(用户 id),username(用户名),password(密码)

User 表索引:uni_username(username) 用户名唯一索引。
Video 表字段:id(视频 id),user_id(用户 id),title(视频标题),play_url(视频地址),cover_url(封面地址),create_time(创建时间,秒级时间戳)

Video 表索引:idx_create_time(create_time) 创建时间普通索引,idx_user_id(user_id) 用户 id 普通索引。

Follow 表字段:follower_id(粉丝用户 id),following(关注用户 id),create_time(创建时间,秒级时间戳)。

Follow 表索引:idx_following(following)关注用户 id 普通索引。

Favorite 表字段:user_id(点赞用户 id),video_id(点赞视频 id),create_time(创建时间,秒级时间戳)。

Favorite 表索引:idx_video_id(video_id)视频 id 普通索引,idx_create_time(create_time) 创建时间普通索引。

Comment 表字段:id(评论 id),video_id(视频 id),user_id(用户 id),content(评论内容),create_time(创建时间)。
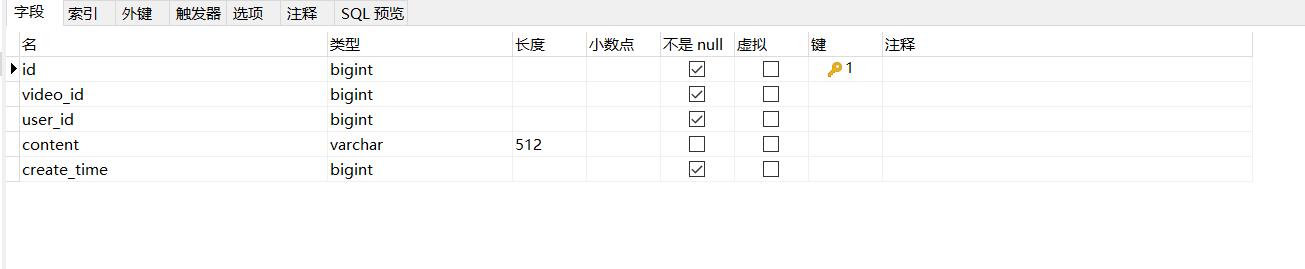
Comment 表索引:idx_create_time(create_time)创建时间普通索引。

3. 用户服务
缓存设计
用户信息缓存: Redis Hash 类型,field-value 存储 username(用户名),follow count(关注数),follower count(粉丝数)。默认过期时间: 12h,超过 10w 粉丝或关注数的用户将不设置过期时间。
最近关注列表缓存: Redis Zset 类型,member 存储关注用户 id,score 为关注时间戳。默认为每个用户维护最多 30 位关注用户列表,过期时间: 1h。
最新粉丝列表缓存: Redis Zset 类型,member 存储粉丝用户 id,score 为关注时间戳。默认为每个用户维护最多 30 位粉丝用户列表,过期时间: 1h。
功能设计
用户注册: 简单的注册逻辑。首先检查密码是否超过 32 个字符(长度限制),然后再检查用户名是否已存在,如果不存在则可以进行注册。这里使用雪花算法生成用户 id,以及将密码进行加密后,使用数据库存储密文密码。最后需要给用户返回一个期限为 1 天的 jwt,也通过它做到注册成功后自动登录账号的效果。
用户登录: 简单的登录逻辑。校验用户名和密文密码是否相同,登录成功返回一个期限为 1 天的 jwt。
获取用户信息: 这个接口需要返回不少用户相关信息。首先需要查询”我“是否关注了指定用户。通过“我”最近关注的 30 位用户缓存来查找指定用户 id 是否存在,如果缓存不存在还需要到数据库中查 Follow 表。然后从缓存中获取查询对象用户名,关注数,粉丝数,这三个查询操作使用 lua 脚本包装,一次 Redis 查询返回三种数据。然后分别看看这三种数据在缓存中是否存在,如果不存在还需要到数据库查询。如果存在其中一种数据不存在于缓存中,我们还需要更新缓存数据。三种数据的更新操作也是在同一个 lua 脚本完成的,使用了 HSETNX 保证只更新不存在的缓存,不会覆盖已有的缓存,否则有可能会覆盖掉刚更新过的数据。最后将用户信息 Json 返回给客户端。
关注操作: 关注操作又分为关注和取消关注。
关注:首先到数据库中查找双方用户 id 是否存在(其实这里可以先查缓存,可能是忘记了),存在后先更新数据库,也就是向 Follow 表添加该关注记录,我们不用检查是否用户是否已关注该对象,因为关注关系双方的 id 做联合主键,不会插入相同的关注记录,相同会报错。最后更新双方用户在 Redis 中缓存的最新关注列表以及最新粉丝列表。
取消关注:首先到数据库中删除该关注记录,然后更新双方用户在 Redis 中缓存的最新关注列表以及最新粉丝列表。
获取关注列表: 首先到每位用户的最近关注列表缓存中进行查询,每位用户缓存最近关注的 30 位用户信息。如果缓存为空,或者缓存了 30 位,前者属于缓存不存在,后者的情况是该用户可能关注的用户超过 30 位,都需要到数据库继续查找。最后将从缓存和数据库获取的用户信息整合并返回给客户端。
获取粉丝列表: 每位用户也缓存了最近关注自己的 30 位用户信息,即最新粉丝列表。具体流程就和获取关注列表相同。
4. 视频服务
缓存设计
视频信息缓存: Redis String 类型,key: VideoId:VideoInfo:{视频id},value: 视频信息 json。默认过期时间:12小时。
用户最新发布视频列表缓存: Redis Zset 类型,key: UserId:VideoId:ZSET:{用户id},member: {视频id},score: 视频创建时间戳。默认过期时间:12小时。
Feed 流缓存: Redis Zset 类型,key: Feed,member: 视频信息 json,score: 视频时间戳。视频信息缓存存储了视频信息,而 Feed 流缓存也选择冗余存储了视频信息,是因为 Feed 缓存默认配置的数值不大(3000 条最新视频),所以可以放心进行冗余存储。
用户最近点赞视频列表缓存: Redis Zset 类型,key: UserId:VideoId:ZSET:{用户id}, members:{视频id} ,score: 点赞时间戳。为用户维护一个最新点赞的 30 个视频 id 的有序集合,假设有 1000 万用户的有序集合存在会占用约 6G 内存空间。我们为每个用户的缓存设置默认 12 小时的过期时间,用于淘汰不活跃用户的缓存。
视频点赞数缓存: Redis String 类型,key: VideoId:FavoriteCount:{视频id},value: 点赞数。我们为每个用户的缓存设置默认 12 小时的过期时间,用于淘汰不活跃用户的缓存。
最近取消点赞视频缓存: Redis Set 类型,key: UserId:DelFavoriteVideoId:SET:{用户id},member: {视频id}。为用户维护一个最近取消点赞的视频 id 的集合,这是由于异步写库,会导致用户取消点赞之后再次刷新同视频时,因为缓存查不到用户最近对该视频的点赞之后直接去查库,得到仍在点赞状态的脏信息,为了防止出现这种状况,我们为每个用户维护一个最近取消点赞视频的集合。在取消点赞时将视频 id 加入集合,而写入数据库后会将该 id 从集合中去除,缓存设置 5 分钟的过期时间,5 分钟未被访问则销毁,这里的销毁当集合为空时也应执行删除操作,如果 5 分钟未访问且尚未因空集而被销毁,大概率是消息消费失败了,可以试着重试消息,但我暂时就不实现了~
视频最新评论信息缓存: Redis String 类型,key: CommentId:Comment:{评论id},value: 评论信息 json。为视频维护一个最新的 30 条评论信息 json 缓存,默认 12 小时的过期时间,用于淘汰冷门视频的评论缓存。
视频最新评论 id 缓存: Redis Zset 类型,key: VideoId:CommentId:ZSET:{视频id},members:{评论id},score: 创建时间。为视频维护一个最新的 30 条评论 id 的有序集合,默认 12 小时的过期时间,用于淘汰冷门视频的评论缓存。评论 id 用于到视频最新评论信息缓存获取真正数据。
视频评论数缓存: Redis String 类型,key: VideoId:CommentCount:{视频id},value: 评论数。默认 12 小时的过期时间,用于淘汰冷门视频的评论缓存。
功能设计
获取 Feed 流(最新视频): 先从 Feed 缓存中获取最新 30 条视频,如果获取的视频信息数量少于 30,还需要到数据库中继续查询。然后返回视频信息和其中最早的视频创建时间戳给客户端,客户端下次继续获取 Feed 流时带上这个时间戳,服务端以这个时间戳作为最新时间,获取该时间戳之前的 30 条视频信息返回给客户端。
点赞: 点赞分为点赞和取消点赞两种操作。点赞是流量最大的一类功能,我采取的是先更新缓存,然后将更新数据库消息通过 Kafka 异步传给独立的进程,让它负责更新数据库。
点赞:先更新 Redis 相关缓存,即视频点赞数 + 1 和将视频 id 写入用户最新点赞视频有序集合,然后将更新数据库消息放进 Kafka 中,便可以响应用户请求,让后台异步更新数据库。
取消点赞:先更新 Redis 相关缓存,即视频点赞数 - 1 和将视频 id 从用户最新点赞视频有序集合中删除,同时要将该视频 id 加入到用户最近取消点赞的视频集合,因为异步写库带来的延迟可能会导致刷新后仍然在已点赞状态,所以我们用最近取消点赞的视频集合缓存来辅助判断是否点赞过该视频,当写库完成时会将该视频 id 从集合中删除。随后就是制造请求消息,之后将请求写入消息队列,让其它进程异步从数据库中删除点赞数据,删除成功后还负责将视频 id 从用户最近取消点赞的视频集合缓存中去除。
负责处理点赞和取消点赞请求的进程具体实现还有一些细节,例如消费失败缓存回滚,大家可以自己看源码了解:源码链接
评论: 评论分为评论和删除评论两种操作。
评论:使用雪花算法生成评论 id,之后先写入数据库,再写入缓存(为什么不是删缓存?因为评论 id 保证唯一,不涉及冲突创建同个评论信息。这个项目只有创建和删除评论操作,但是如果说有更新评论的操作则需要删缓存。)。
删除评论:先从数据库中删除该评论信息,再删除相关缓存。
获取用户发布视频列表: 首先获取缓存中的最新发布视频列表(json 格式信息),如果不存在该用户的缓存,或者缓存列表已满,则需要到数据库中查找该用户是否还有发布的视频。(可靠性不是很好,如果某视频发布的时候更新缓存出现失败,那么这个视频将一段时间无法被查询到,直到用户又发布了 30 条新视频占满最新发布视频列表,那么会从 DB 中查询到该视频数据)。之后就是将接口要求的一些字段从缓存中获取,获取不到到数据库找,找到了更新缓存的过程,最后包装成需要返回的 json 格式信息返回给客户端。
获取视频评论列表: 原理同上。
获取用户点赞过的视频列表: 原理同上。
5. 鉴权服务
功能设计
鉴权采用的是 JWT,一共有三个功能:创建 Token,解析 Token,验证 Token 是否有效(暂未使用,因为解析 Token 顺便就能验证了)。这些功能实现的具体流程只是调 JWT 包,就不说明了,如果不会使用 JWT 包可以查看源码:源码链接
6. 投稿转码服务
功能设计
视频转码: api 层首先将客户端发送过来的视频校验格式,然后上传到 OSS 的待处理视频文件夹中,将请求消息通过 Kafka 发送给投稿服务后即可响应客户端(所以用户会延迟一会儿才能刷到自己新发布的视频)。视频转码服务大约每秒从 Kafka 拉取一轮消息,然后解析消息,得到投稿用户 id 以及视频标题,视频在 OSS 里的 Object Key,接着就可以开始具体的处理了,处理流程如下:
- 从 OSS 下载待处理的视频文件。
- 调用 ffmpeg 视频转码与截取封面(请确保本地安装了 ffmpeg,并设置了环境变量)。
- 将转码后视频与封面上传至 OSS。
- 将视频信息写入数据库和缓存。
- 将 OSS 中的原视频删除。
7. 结语
好了,终于把两个月前挖的坑填好了,我这个项目为了性能,降低了一些可靠性。大家如果要做一个同类项目的话,可以借鉴一下我在缓存方面的设计,以及 lua 脚本的封装。除此之外,还可以做一些提高可靠性的改进,比如增加消费失败的重试功能。祝大家可以做出更优秀的项目哦。🍭🍭



