Redis学习笔记(2):字符串类型基本API
1. Redis字符串简介
字符串类型是Redis中最基本的数据结构,金毛站长发现基本所有的Redis教学书籍或文档都会先从字符串类型开始让初学者入门。
像《Redis开发与运维》的说法是键都是字符串类型,而且其他四种基本数据结构(hash,list,set,zset)都是在字符串类型基础上构建的,所以字符串类型能为其他四种数据结构的学习奠定基础。《Redis深度历险:核心原理与应用实践》的说法是Redis所有的数据结构都以唯一的key字符串作为名称,然后通过这个唯一的key值来获取相应的value数据。不同类型的数据结构差异就在于value的结构不一样。站长我现在也是Redis初学者,我来讲讲目前我对Redis中字符串的理解,顺便也为字符串类型做一个简单介绍。
2. Redis字符串类型常用API
set命令:
set {key} {value} ,添加或更新,添加成功返回OK (扩展参数:ex {seconds}为键设置秒级过期时间,px {milliseconds}:为键设置毫秒级过期时间,nx:键必须不存在,才可以设置成功,用于添加。 xx,与nx相反,键必须存在才可以设置成功,用于更新。}
# set示例
127.0.0.1:6379> set name eriri
OK
127.0.0.1:6379> set name eriri nx
(nil)
127.0.0.1:6379> set name Eriri xx
OK
#设置过期时间3s
127.0.0.1:6379> set name Eriri ex 3
OK
#三秒后获取,name已经被删除,返回nil
127.0.0.1:6379> get name
(nil)
setnx命令:
setnx {key} {value}, 键不存在才能添加成功,成功返回1,不成功返回0。
# setnx示例
127.0.0.1:6379> setnx name Eriri
(integer) 1
127.0.0.1:6379> setnx name eriri
(integer) 0
127.0.0.1:6379> get name
"Eriri"
由于Redis的单线程命令处理机制,如果有多个客户端同时执行setnx key value,根据setnx的特性只有一个客户端能设置成功,setnx可以作为分布式锁的一种实现方案。
setex命令:
setex {key} {seconds} {value} ,添加或更新原有key的值,并设置过期时间seconds,以秒为单位,成功返回OK。
# setex示例
127.0.0.1:6379> setex name 5 eriri
OK
127.0.0.1:6379> get name
"eriri"
# 5s之后
127.0.0.1:6379> get name
(nil)
mset命令:
mset {key1} {value1} {key2} {value2}… ,批量设置键值对,成功时返回OK。
#示例
127.0.0.1:6379> mset name1 eriri name2 megumi
OK
get命令:
get {key} ,获取值,若键存在返回对应的值,不存在返回nil。
# 示例
127.0.0.1:6379> set name eriri
OK
127.0.0.1:6379> get name
"eriri"
127.0.0.1:6379> get eriri
(nil)
mget命令:
mget {key} {key}… ,批量获取值,若键存在返回对应的值,不存在返回nil。
# 示例
127.0.0.1:6379> mset name1 eriri name2 megumi
OK
127.0.0.1:6379> mget name1 name2 name3
1) "eriri"
2) "megumi"
3) (nil)
Redis可以支撑每秒数万的读写操作,但是这指的是Redis服务端的处理能力,对于客户端来说,一次命令除了命令时间还是有网络时间,假设网络时间为1毫秒,命令时间为0.1毫秒(按照每秒处理1万条命令算),那么执行1000次get命令和1次mget命令的区别如表2-1,因为Redis的处理能力已经足够高,对于开发人员来说,网络可能会成为性能的瓶颈。学会使用批量操作,有助于提高业务处理效率,但是要注意的是每次批量操作所发送的命令数不是无节制的,如果数量过多可能造成Redis阻塞或者网络拥塞。
del命令:
del {key1} {key2}… ,删除指定的键,返回结果为成功删除键的总数。
# 示例
127.0.0.1:6379> mset name1 eriri name2 megumi
OK
127.0.0.1:6379> mget name1 name2
1) "eriri"
2) "megumi"
127.0.0.1:6379> del name1 name2
(integer) 2
127.0.0.1:6379> mget name1 name2
1) (nil)
2) (nil)
exists命令:
**exists {key1} {key2}**,检查键是否存在,返回存在的键总数。
# 示例
127.0.0.1:6379> mset name1 eriri name2 megumi
OK
127.0.0.1:6379> exists name1 name2 name3
(integer) 2
127.0.0.1:6379> exists name3
(integer) 0
expire && ttl命令:
expire {key} {seconds}, 设置键过期时间,成功返回1,若键不存在返回0。
ttl {key} 返回键的剩余过期时间,有3种返回值:大于等于0的整数为键剩余过期时间,-1为键没设置过期时间,-2为键不存在。
# 示例
127.0.0.1:6379> set name eriri
OK
#此时没给name设置过期时间,ttl返回-1
127.0.0.1:6379> ttl name
(integer) -1
#设置name过期时间为5s
127.0.0.1:6379> expire name 5
(integer) 1
#此时用ttl name查询name过期时间,过期时间还剩4s
127.0.0.1:6379> ttl name
(integer) 4
127.0.0.1:6379> get name
"eriri"
#5s之后name已过期,ttl name返回-2
127.0.0.1:6379> ttl name
(integer) -2
127.0.0.1:6379> get name
(nil)
自增和自减命令:
自增和自减有多个命令,这里把它们归为一类来介绍。
incr {key} ,对该键的值进行自增操作,每次加1,值不是整数会报错,值是整数则返回自增后的结果,键不存在则会创建并按照值原本为0自增,返回1。
decr {key} ,对该键的值进行自减操作,每次减1,值不是整数报错,是整数则返回自减后的结果,键不存在则会创建并按照值为0自减,返回-1
incrby {key}{increment} ,令该键的值加上指定数字(increment),值不是整数会报错,返回增加后的结果,键不存在则会创建并按照值原本为0加上increment,之后返回增加后的数值。
decrby {key} {decrement} ,令该键的值减去指定数字(decrement),值不是整数会报错,返回相减后的结果,键不存在则会创建并按照值原本为0减去decrement,之后返回相减后的数值。
incrbyfloat {key} {increment} ,令该键的值加上指定数字(increment),值不是纯数字会报错,返回增加后的结果,键不存在则会创建并按照值原本为0加上increment,之后返回增加后的数值。
# 示例
127.0.0.1:6379> set v1 2
OK
127.0.0.1:6379> incr v1
(integer) 3
127.0.0.1:6379> decr v1
(integer) 2
127.0.0.1:6379> incrby v1 2
(integer) 4
127.0.0.1:6379> decrby v1 2
(integer) 2
127.0.0.1:6379> incrbyfloat v1 2.5
"4.5"
#incrbyfloat后v1为4.5,不再是整数,incr会报错
127.0.0.1:6379> incr v1
(error) ERR value is not an integer or out of range
#再使用incrbyfloat给v1加上0.5后变成5,此时可以使用incr
127.0.0.1:6379> incrbyfloat v1 0.5
"5"
127.0.0.1:6379> incr v1
(integer) 6
type命令:
type {key} ,返回key的数据类型,不存在返回none。
127.0.0.1:6379> set name eriri
OK
127.0.0.1:6379> type name
string
127.0.0.1:6379> lpush game cs
(integer) 1
127.0.0.1:6379> type game
list
object encoding命令:
object encoding {key} ,返回该key的数据结构内部编码方式。
# 示例
127.0.0.1:6379> set v1 10
OK
127.0.0.1:6379> object encoding v1
"int"
127.0.0.1:6379> set name eriri
OK
127.0.0.1:6379> object encoding name
"embstr"
127.0.0.1:6379> set v2 aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
OK
127.0.0.1:6379> object encoding v2
"raw"
dbsize命令:
dbsize ,返回当前数据库的所有键总数。
# 示例
127.0.0.1:6379> set name eriri
OK
127.0.0.1:6379> dbsize
(integer) 1
keys命令:
keys * ,查看当前数据库的所有键名。keys {key} 查看该键是否存在,存在返回键名,不存在返回(empty list or set)。
# 示例
127.0.0.1:6379> mset name1 eriri name2 megumi
OK
127.0.0.1:6379> keys *
1) "name2"
2) "name1"
127.0.0.1:6379> keys name1
1) "name1"
127.0.0.1:6379> keys name3
(empty list or set)
flushdb/flushall命令:
flushdb和flushall命令都可以清空数据库,但是两者是有所区别的。flushall是清空所有的数据库,flushdb只删除当前正在使用的数据库的数据。
# 示例 默认使用0号数据库,redis默认有16个数据库,索引0~15
127.0.0.1:6379> set name eriri
OK
#使用keys * 获取所有的键
127.0.0.1:6379> keys *
1) "name"
#select {index} 切换到指定索引的数据库,以下为切换到db1
127.0.0.1:6379> select 1
OK
127.0.0.1:6379[1]> set name megumi
OK
127.0.0.1:6379[1]> keys *
1) "name"
127.0.0.1:6379[1]> flushdb
OK
#db1使用flushdb后,把自己清空了
127.0.0.1:6379[1]> keys *
(empty list or set)
#切换回db0
127.0.0.1:6379[1]> select 0
OK
#使用keys * 发现name依然存在
127.0.0.1:6379> keys *
1) "name"
#以下为切换回db1并执行flushall,清空所有数据库
127.0.0.1:6379> select 1
OK
127.0.0.1:6379[1]> flushall
OK
#切换回db0并执行keys *,发现db0已被清空
127.0.0.1:6379[1]> select 0
OK
127.0.0.1:6379> keys *
(empty list or set)
另外多插一嘴,关于误操作flushdb或flushall后的恢复操作,这些操作是站长亲自试验成功分享给大家的( •̀ ω •́ )✧。
首先为了误操作后能够恢复,要把AOF持久化打开,这是一种写日志的持久化方式,每当Redis执行一个改变数据集的命令时,这个命令就会被记录和追加到AOF文件的末尾。打开AOF首先得在redis.conf中找到appendonly no,修改为appendonly yes。使用vim可以快速查找到该句,执行vim redis.conf打开redis.conf后,首先输入/aof,然后按ESC进入普通模式,然后按N向下搜索关键字(小写n为向上搜索),找到appendonly no修改。修改保存后,重启一下redis-server,重启可以进redis-cli执行shutdown或者直接kill掉redis进程,重启后即可启用AOF。(不知道redis.conf在哪的可以参考一下,站长的redis.conf目录在/etc/redis/redis.conf)
以下用flushall示例,flushdb同理,操作环境是阿里云轻量应用服务器Ubuntu20.04。
# 原本db中是有1个key的
127.0.0.1:6379> keys *
1) "name"
127.0.0.1:6379> dbsize
(integer) 1
#flushall后被清空
127.0.0.1:6379> flushall
OK
127.0.0.1:6379> keys *
(empty list or set)

执行flushall/flushdb后,退出redis-cli,之后找到appendonly.aof(站长的在/var/lib/redis/appendonly.aof),可以看到该文件记录了很多命令,用顶部的一些命令来解释一下:
*2 //代表这个命令有两个参数
$6 //代表接下来的参数(第一个参数)字符长度为6
SELECT //第一个参数
$1 //代表接下来的参数(第二个参数)字符长度为1
0 //第二个参数
//看出来了吧?原本的这句命令就是SELECT 0
看到最底部的一句是刚刚执行的flushall,把flushall删除掉,之后退出并保存。最后令redis重启,可以用kill或者进入redis-cli使用shutdown,以下演示kill方法,让redis先关闭后重启,命令在下面:
# 第一句为查找redis的进程号
ps -aux | grep redis
root 16068 0.0 0.5 24396 9720 pts/0 T 09:07 0:00 vi redis.conf
# redis在这
redis 16510 0.1 0.3 68148 6064 ? Ssl 09:32 0:04 /usr/bin/redis-server 127.0.0.1:6379
root 16562 0.0 0.5 24512 9996 pts/0 T 09:44 0:00 vi redis.conf
root 16626 0.0 0.1 8436 2584 pts/0 T 10:03 0:00 less /var/lib/redis/appendonly.aof
root 16708 0.0 0.0 9032 724 pts/0 S+ 10:21 0:00 grep --color=auto redis
#kill掉redis的进程号
kill 16510
此时再进入redis查看,可以发现key恢复了。
127.0.0.1:6379> dbsize
(integer) 1
127.0.0.1:6379> keys *
1) "name"
3. 字符串类型不常用API
append命令:
append {key} {value} ,向字符串尾部追加值,返回新值的长度。不存在则创建该key并以原来为空串追加。
# 示例
127.0.0.1:6379> append name eri
(integer) 3
127.0.0.1:6379> get name
"eri"
127.0.0.1:6379> append name ri
(integer) 5
127.0.0.1:6379> get name
"eriri"
127.0.0.1:6379> append name 233
(integer) 8
127.0.0.1:6379> get name
"eriri233"
# 注意,append是往尾部加入字符,所以给字符串值1加入一个1后是11,而不是1+1=2
127.0.0.1:6379> set v1 1
OK
127.0.0.1:6379> append v1 1
(integer) 2
127.0.0.1:6379> get v1
"11"
127.0.0.1:6379> append v1 err
(integer) 5
127.0.0.1:6379> get v1
"11err"
strlen命令:
strlen {key} ,返回字符串的长度,不存在为0。若是中文或中文符号,每个字占3个字节。
# 示例
127.0.0.1:6379> set name eriri
OK
127.0.0.1:6379> strlen name
(integer) 5
127.0.0.1:6379> set chinese 英梨梨
OK
127.0.0.1:6379> strlen chinese
(integer) 9
#向英梨梨后加入一个中文逗号,可以看到append返回的新值长度为12,中文符号也占3字节
127.0.0.1:6379> append chinese ,
(integer) 12
getset命令:
getset {key} {value} ,先get后set,会先返回原先的值,原先不存在为nil。
# 示例
127.0.0.1:6379> set name eriri
OK
127.0.0.1:6379> getset name Eriri
"eriri"
127.0.0.1:6379> get name
"Eriri"
127.0.0.1:6379> getset name2 megumi
(nil)
127.0.0.1:6379> get name2
"megumi"
setrange命令:
setrange {key} {offset} {value} ,设置指定位置的字符,offset为对首字符的偏移量,返回字符串长度,若不存在则会创建字符串,偏移量前的字符会用\x00(即二位十六进制,0x00,ASCII值代表NULL)补上。
# 示例
127.0.0.1:6379> set name eriri
OK
127.0.0.1:6379> setrange name 0 E
(integer) 5
127.0.0.1:6379> get name
"Eriri"
#创建先前不存在的name2,并将第四个字符设成g(要设置字符的地址为首字符+(偏移量)3)
127.0.0.1:6379> setrange name2 3 g
(integer) 4
127.0.0.1:6379> get name2
"\x00\x00\x00g"
getrange命令:
getrange {key} {start} {end} ,获取偏移量为start至end的字符串,start和end分别是开始和结束的偏移量,首字符偏移量为0。
# 示例
127.0.0.1:6379> set name eriri
OK
127.0.0.1:6379> getrange name 1 4
"riri"
#获取存在的键,但超出偏移量范围,返回""
127.0.0.1:6379> getrange name 5 7
127.0.0.1:6379> getrange name 5 7
""
#获取不存在的键,返回\x00
127.0.0.1:6379> getrange name2 1 3
"\x00\x00g"
表2-2是字符串类型命令的时间复杂度,开发人员可以参考此表,结合 自身业务需求和数据大小选择适合的命令。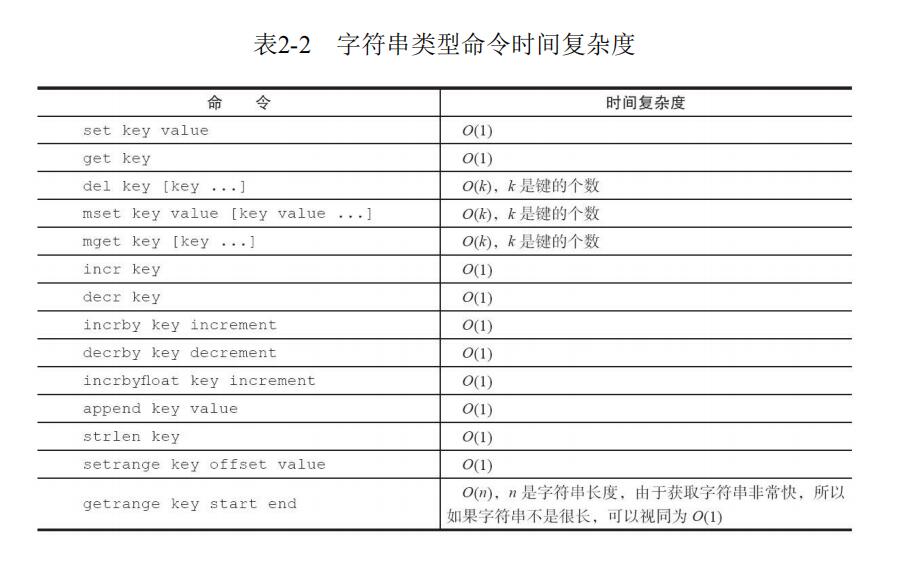
4. 字符串类型典型使用场景
1.缓存功能
下图是比较典型的Redis缓存应用场景,其中Redis作为缓存层,MySQL作为存储层,绝大部分数据都是从缓存层获取。由于Redis具有支撑高并发的特性,所以缓存通常能起到加速读写和降低后端压力的作用。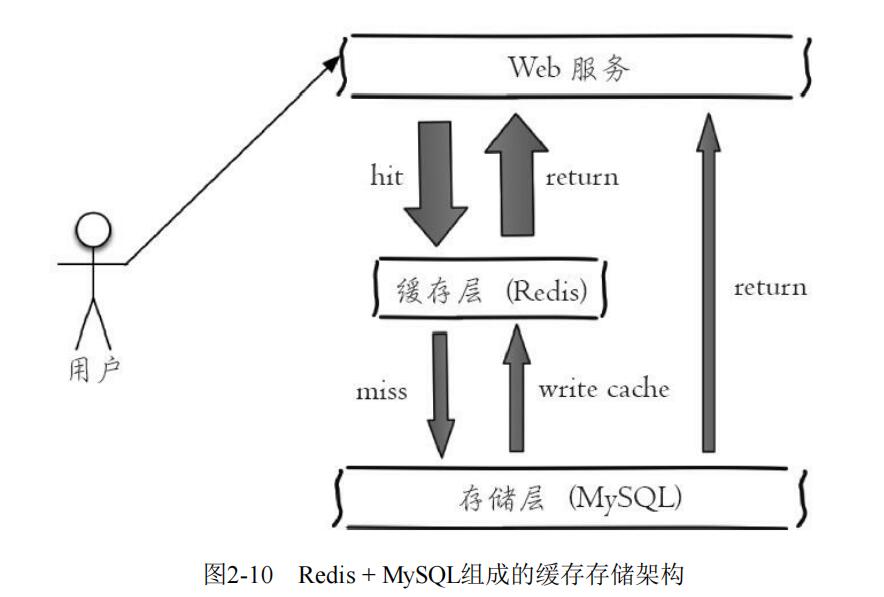
该存储架构的意思是,假如Web前台需要获取用户信息,首先向缓存层(Redis)发起获取请求,若缓存层存在该用户信息则直接返回给前台。若缓存层没有该用户的信息,即缓存未命中,就向存储层(MySQL)发起获取请求,若存储层依然找不到该用户信息就是真的不存在了。而如果存在该用户信息,就将用户信息取出并向缓存层存入该用户的信息,再返回给前台。为了防止缓存太多导致缓存层空间爆满可以设置一个过期时间,比如1h。
2. 计数
许多应用都会使用Redis作为计数的基础工具,它可以实现快速计数、查询缓存的功能,同时数据可以异步落地到其他数据源。比如视频播放数的计数一般使用Redis实现。
实际上一个真实的计数系统要考虑的问题会很多:防作弊、按照不同维度计数,数据持久化到底层数据源等。
3. 共享Session
一个分布式Web服务将用户的Session信息(例如用户登录信息)保存在各自服务器中,这样会造成一个问题,出于负载均衡的考虑,分布式服务会将用户的访问均衡到不同服务器上,用户刷新一次访问可能会发现需要重新登录,这个问题是用户无法容忍的。为了解决这个问题,可以使用Redis将用户的Session进行集中管理,如图所示,在这种模式下只要保证Redis是高可用和扩展性的,每次用户更新或者查询登录信息都直接从Redis中集中获取。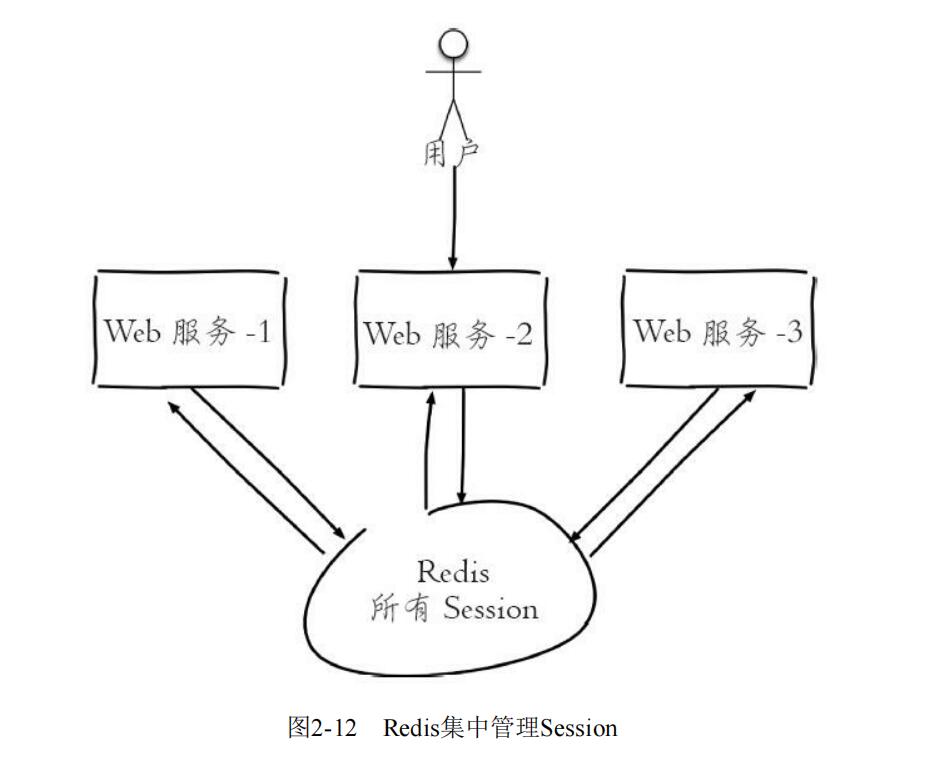
4. 限速
很多应用出于安全的考虑,会在每次进行登录时,让用户输入手机验证码,从而确定是否是用户本人。但是为了短信接口不被频繁访问,会限制用户每分钟获取验证码的频率,例如一分钟不能超过5次。
# 伪代码实现示例
phoneNum = "138xxxxxxxx";
key = "shortMsg:limit:" + phoneNum;
// SET key value EX 60 NX
isExists = redis.set(key,1,"EX 60","NX");
if(isExists != null || redis.incr(key) <=5){
// 通过 }
else{
// 限速
}
5. 关于一些能改变内部编码的API与源码分析
这些会导致改变字符串内部编码的API都是金毛站长瞎搞发现的…可能我所发现的还不是全部的能改变字符串内部编码的API,如果你还知道哪些可以改变内部编码的API可以在下方留言。
1. append命令
对已存在的字符串值使用append命令后,无论字符串值原先是什么内部编码,都会变成raw。
# 示例
127.0.0.1:6379> set name eriri
OK
127.0.0.1:6379> object encoding name
"embstr"
127.0.0.1:6379> append name ya
(integer) 7
127.0.0.1:6379> object encoding name
"raw"
127.0.0.1:6379> set v1 1
OK
127.0.0.1:6379> object encoding v1
"int"
127.0.0.1:6379> append v1 1
(integer) 2
127.0.0.1:6379> object encoding name
"raw"
127.0.0.1:6379> set name aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
OK
127.0.0.1:6379> object encoding name
"raw"
127.0.0.1:6379> append name 10
(integer) 51
127.0.0.1:6379> object encoding name
"raw"
# 但是利用append创建一个新键依然会根据规则选择内部编码
127.0.0.1:6379> append test 1
(integer) 1
127.0.0.1:6379> object encoding test
"int"
为什么对原有的字符串进行append,都会变成raw编码呢?对于这种事,应该从append源码入手分析:
void appendCommand(client *c) {
size_t totlen;
robj *o, *append;
o = lookupKeyWrite(c->db,c->argv[1]);
if (o == NULL) {
/* Create the key */
c->argv[2] = tryObjectEncoding(c->argv[2]);
dbAdd(c->db,c->argv[1],c->argv[2]);
incrRefCount(c->argv[2]);
totlen = stringObjectLen(c->argv[2]);
} else {
/* Key exists, check type */
if (checkType(c,o,OBJ_STRING))
return;
/* "append" is an argument, so always an sds */
append = c->argv[2];
totlen = stringObjectLen(o)+sdslen(append->ptr);
if (checkStringLength(c,totlen) != C_OK)
return;
/* Append the value */
o = dbUnshareStringValue(c->db,c->argv[1],o);
o->ptr = sdscatlen(o->ptr,append->ptr,sdslen(append->ptr));
totlen = sdslen(o->ptr);
}
signalModifiedKey(c,c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_STRING,"append",c->argv[1],c->db->id);
server.dirty++;
addReplyLongLong(c,totlen);
}
对于Append the value时的第一句 “o = dbUnshareStringValue(c->db,c->argv[1],o)” ,接下来再看看它的源码:
robj *dbUnshareStringValue(redisDb *db, robj *key, robj *o) {
serverAssert(o->type == OBJ_STRING);
if (o->refcount != 1 || o->encoding != OBJ_ENCODING_RAW) {
robj *decoded = getDecodedObject(o);
o = createRawStringObject(decoded->ptr, sdslen(decoded->ptr));
decrRefCount(decoded);
dbOverwrite(db,key,o);
}
return o;
}
“o = createRawStringObject(decoded->ptr, sdslen(decoded->ptr))” 虽然我的水平看不懂源码的一些东西,但是在这一句所调用的函数名已经很明显了,不过我们可以再继续进这个函数里看:
robj *createRawStringObject(const char *ptr, size_t len) {
return createObject(OBJ_STRING, sdsnewlen(ptr,len));
}
最后看看createObject函数:
robj *createObject(int type, void *ptr) {
robj *o = zmalloc(sizeof(*o));
o->type = type;
o->encoding = OBJ_ENCODING_RAW;
o->ptr = ptr;
o->refcount = 1;
/* Set the LRU to the current lruclock (minutes resolution), or
* alternatively the LFU counter. */
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL;
} else {
o->lru = LRU_CLOCK();
}
return o;
}
在createObject函数中,可以看到 “o->encoding = OBJ_ENCODING_RAW” ,即使看不太懂源码但也可以通过英文意思看得出来,这里新建的是一个raw编码的字符串了。
2. setrange命令
使用setrange命令无论是创建一个新的字符串,还是更改现有的字符串,它们都是raw编码。
# 示例
127.0.0.1:6379> set name eriri
OK
127.0.0.1:6379> object encoding name
"embstr"
127.0.0.1:6379> setrange name 0 E
(integer) 5
127.0.0.1:6379> get name
"Eriri"
127.0.0.1:6379> object encoding name
"raw"
# 使用setrange创建
127.0.0.1:6379> setrange name2 0 m
(integer) 1
127.0.0.1:6379> get name2
"m"
127.0.0.1:6379> object encoding name2
"raw"
让我们继续通过setrange的源码分析一下为什么会这样:
void setrangeCommand(client *c) {
robj *o;
long offset;
sds value = c->argv[3]->ptr;
if (getLongFromObjectOrReply(c,c->argv[2],&offset,NULL) != C_OK)
return;
if (offset < 0) {
addReplyError(c,"offset is out of range");
return;
}
o = lookupKeyWrite(c->db,c->argv[1]);
if (o == NULL) {
/* Return 0 when setting nothing on a non-existing string */
if (sdslen(value) == 0) {
addReply(c,shared.czero);
return;
}
/* Return when the resulting string exceeds allowed size */
if (checkStringLength(c,offset+sdslen(value)) != C_OK)
return;
//key不存在时使用createObject创建
o = createObject(OBJ_STRING,sdsnewlen(NULL, offset+sdslen(value)));
dbAdd(c->db,c->argv[1],o);
} else {
size_t olen;
/* Key exists, check type */
if (checkType(c,o,OBJ_STRING))
return;
/* Return existing string length when setting nothing */
olen = stringObjectLen(o);
if (sdslen(value) == 0) {
addReplyLongLong(c,olen);
return;
}
/* Return when the resulting string exceeds allowed size */
if (checkStringLength(c,offset+sdslen(value)) != C_OK)
return;
/* Create a copy when the object is shared or encoded. */
//key存在时使用dbUnshareStringValue方法
o = dbUnshareStringValue(c->db,c->argv[1],o);
}
if (sdslen(value) > 0) {
o->ptr = sdsgrowzero(o->ptr,offset+sdslen(value));
memcpy((char*)o->ptr+offset,value,sdslen(value));
signalModifiedKey(c,c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_STRING,
"setrange",c->argv[1],c->db->id);
server.dirty++;
}
addReplyLongLong(c,sdslen(o->ptr));
}
可以看到使用setrange创建字符串时调用的是createObject方法,在上面的append源码分析我们就看到过,它是使用raw编码创建的。如果使用setrange修改存在的字符串,会调用dbUnshareStringValue方法,也是通过之前的源码分析可以知道这个方法最终还是会调用createObject ,所以最后也是个raw编码字符串。
3. incrbyfloat命令
内部编码为int的整数使用incrbyfloat之后,即使结果依然看起来是一个整数,但是内部编码方式不再是int,而只能是embstr和raw,会根据变化后的值长度来选择。
# 示例
127.0.0.1:6379> set v1 1
OK
127.0.0.1:6379> object encoding v1
"int"
127.0.0.1:6379> incrbyfloat v1 0.5
"1.5"
127.0.0.1:6379> object encoding v1
"embstr"
127.0.0.1:6379> set v2 1
OK
127.0.0.1:6379> object encoding v2
"int"
127.0.0.1:6379> incrbyfloat v2 1
"2"
127.0.0.1:6379> object encoding v2
"embstr"
127.0.0.1:6379> set v3 1
OK
127.0.0.1:6379> incrbyfloat v3 1e44
# 很明显,出现了浮点数精度问题,不过重点不在这
"100000000000000000001038625398088182045605888"
127.0.0.1:6379> strlen v3
(integer) 45
127.0.0.1:6379> object encoding v3
"raw"
我们通过incrbyfloat源码分析一下为什么会出现这样的情况:
void incrbyfloatCommand(client *c) {
long double incr, value;
robj *o, *new;
o = lookupKeyWrite(c->db,c->argv[1]);
if (checkType(c,o,OBJ_STRING)) return;
if (getLongDoubleFromObjectOrReply(c,o,&value,NULL) != C_OK ||
getLongDoubleFromObjectOrReply(c,c->argv[2],&incr,NULL) != C_OK)
return;
value += incr;
if (isnan(value) || isinf(value)) {
addReplyError(c,"increment would produce NaN or Infinity");
return;
}
//关键!
new = createStringObjectFromLongDouble(value,1);
if (o)
dbOverwrite(c->db,c->argv[1],new);
else
dbAdd(c->db,c->argv[1],new);
signalModifiedKey(c,c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_STRING,"incrbyfloat",c->argv[1],c->db->id);
server.dirty++;
addReplyBulk(c,new);
/* Always replicate INCRBYFLOAT as a SET command with the final value
* in order to make sure that differences in float precision or formatting
* will not create differences in replicas or after an AOF restart. */
rewriteClientCommandArgument(c,0,shared.set);
rewriteClientCommandArgument(c,2,new);
rewriteClientCommandArgument(c,3,shared.keepttl);
}
关键在于 “new = createStringObjectFromLongDouble(value,1)” 这一句,接着我们来看createStringObjectFromLongDouble方法:
robj *createStringObjectFromLongDouble(long double value, int humanfriendly) {
char buf[MAX_LONG_DOUBLE_CHARS];
int len = ld2string(buf,sizeof(buf),value,humanfriendly? LD_STR_HUMAN: LD_STR_AUTO);
return createStringObject(buf,len);
}
最后是返回的是createStringObject(buf,len) ,接着继续看createStringObject方法:
robj *createStringObject(const char *ptr, size_t len) {
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr,len);
else
return createRawStringObject(ptr,len);
}
结果我们可以发现这个方法里只有两个选项,要么长度小于等于embstr的最大长度限制(44)时创建一个embstr编码的字符串,要么就创建一个raw编码的字符串,所以这也就是为什么使用incrbyfloat后不再出现int编码字符串的原因。
6. 杂谈
这一章写到这总算结束了,写完这一篇文章的时间都够我学好多新的redis命令了。。。但是时不时写一篇比较详细的文章,运用一下费曼学习法大大加深了记忆又何尝不可~嘻嘻🍭🍭不知道下一篇还有没有精力和兴趣想写,总之先预告下一篇会是Hash的基本API介绍啦!



