Redis学习笔记(5):set类型API大全
1. set类型简介
集合(set)类型也是用来保存多个的字符串元素,但和列表类型不一样的是,集合中不允许有重复元素,并且集合中的元素是无序的,不能通过索引下标获取元素,一个集合最多可以存储2^32-1个元素。Redis除了支持集合内的增删改查,同时还支持多个集合取交集、并集、差集,合理地使用好集合类型,能在实际开发中解决很多实际问题。
2. set类型API
1. sadd命令
sadd {key} {member1} {member2…} ,向集合中添加元素(member),支持输入多个member,返回值为成功添加元素的数量。
# 示例
127.0.0.1:6379> sadd test a b c
(integer) 3
127.0.0.1:6379> sadd test a
(integer) 0
2. srem命令
srem {key} {member1} {member2…} ,删除集合中的元素(member),支持一次性批量删除多个member,返回值为成功删除的元素数量。
# 示例
127.0.0.1:6379> sadd test a b c
(integer) 3
127.0.0.1:6379> srem test a
(integer) 1
127.0.0.1:6379> srem test b c
(integer) 2
3. scard命令
scard {key} ,返回集合中的元素个数。该命令的时间复杂度为O(1),它不是遍历一遍集合中的所有元素,而是直接返回记录元素个数的内部变量。
# 示例
127.0.0.1:6379> sadd a a b c
(integer) 3
127.0.0.1:6379> scard a
(integer) 3
4. sismember/smismember命令
sismember {key} {member} ,判断元素是否在集合中。存在返回1,不存在返回0。
smismember {key} {member1} {member2…} ,与sismember相同,判断元素是否在集合中,但是支持输入多个member。存在返回1,不存在返回0。sismember在Redis 6.2.0版本出现。
# 示例
127.0.0.1:6379> sadd b 1 2 3
(integer) 3
127.0.0.1:6379> sismember b 4
(integer) 0
127.0.0.1:6379> sismember b 2
(integer) 1
127.0.0.1:6379> smismember b 2 3 4
1) (integer) 1
2) (integer) 1
3) (integer) 0
5. srandmember命令
srandmember {key} (count) ,srandmember的作用是随机返回count个元素,count可选,缺省时为1。count可以是正数和负数,count为正数时不会返回重复的元素,若count大于集合的元素个数,返回全部元素。若count为负数时,返回的元素中会有重复,一共返回-count次。
# 示例
127.0.0.1:6379> sadd a 1 2 3 4 5
(integer) 5
127.0.0.1:6379> object encoding a
"intset"
# count缺省,随机获取1个元素
127.0.0.1:6379> srandmember a
"2"
# 当集合内部编码为intset时,srandmember获取所有元素时是从小到大有序的
127.0.0.1:6379> srandmember a 5
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
# count为负数,可能出现重复数字
127.0.0.1:6379> srandmember a -10
1) "2"
2) "4"
3) "3"
4) "5"
5) "2"
6) "1"
7) "2"
8) "1"
9) "4"
10) "5"
# 添加一个非整数元素,使内部编码变为hashtable
127.0.0.1:6379> sadd a c
(integer) 1
127.0.0.1:6379> object encoding a
"hashtable"
# hashtable使用srandmember获取所有元素是无序的
127.0.0.1:6379> srandmember a 6
1) "4"
2) "1"
3) "2"
4) "c"
5) "5"
6) "3"
6. spop命令
spop {key} (count) ,从集合中随机弹出元素,弹出后元素会从集合中删除,返回值为所弹出的元素。count为可选参数,缺省为1,count只能为正数。count大于集合的元素个数时弹出所有元素。
# 示例
127.0.0.1:6379> sadd a 1 2 3 4 5
(integer) 5
127.0.0.1:6379> spop a
"3"
127.0.0.1:6379> spop a 2
1) "5"
2) "4"
127.0.0.1:6379> spop a 5
1) "1"
2) "2"
7. smembers命令
smembers {key} ,获取集合中所有元素。
# 示例
127.0.0.1:6379> sadd a 1 2 3 4 5
(integer) 5
# 当集合为intset时获取所有元素的返回值是升序的
127.0.0.1:6379> object encoding a
"intset"
127.0.0.1:6379> smembers a
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
127.0.0.1:6379> sadd a a
(integer) 1
# 当集合为intset时获取所有元素的返回值是无序的
127.0.0.1:6379> object encoding a
"hashtable"
127.0.0.1:6379> smembers a
1) "4"
2) "1"
3) "2"
4) "a"
5) "5"
6) "3"
8. sinter命令
sinter {key1} {key2…} ,返回多个集合的交集。
# 示例
127.0.0.1:6379> sadd a 1 2 3 4 5
(integer) 5
127.0.0.1:6379> sadd b 3 4 5 6 7
(integer) 5
127.0.0.1:6379> sinter a b
1) "3"
2) "4"
3) "5"
127.0.0.1:6379> sadd c 5
(integer) 1
127.0.0.1:6379> sinter a b c
1) "5"
# d是不存在的集合,不存在交集返回empty array
127.0.0.1:6379> sinter a d
(empty array)
9. sunion命令
sunion {key1} {key2…} ,返回多个集合的并集。
# 示例
127.0.0.1:6379> sadd a 1 2 3 4 5
(integer) 5
127.0.0.1:6379> sadd b 3 4 5 6 7
(integer) 5
127.0.0.1:6379> sunion a b
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
10. sdiff命令
sdiff {key1} {key2…} , 返回多个集合的差集。
# 示例
127.0.0.1:6379> sadd a 1 2 3 4 5
(integer) 5
127.0.0.1:6379> sadd b 3 4 5 6 7
(integer) 5
127.0.0.1:6379> sdiff a b
1) "1"
2) "2"
11. sinterstore/sunionstore/sdiffstore命令
sinterstore/sunionstore/sdiffstore destination {key1} {key2…} ,把多个集合的交集,并集或差集保存到destination中,返回的是结果的元素个数。
# 示例
127.0.0.1:6379> sadd a 1 2 3 4 5
(integer) 5
127.0.0.1:6379> sadd b 3 4 5 6 7
(integer) 5
127.0.0.1:6379> sinterstore c a b
(integer) 3
127.0.0.1:6379> sdiffstore c a b
(integer) 2
# 注意,使用此类命令会将destination现有的元素完全替换掉
127.0.0.1:6379> sunionstore c a b
(integer) 7
127.0.0.1:6379> smembers c
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
7) "7"
12. sintercard命令
sintercard {numkeys} {key1} {key2…} (LIMIT) (limit) ,该命令和sinter类似,但是返回的只是交集中元素数量。numkeys为要求交集的key的个数,一定要与后续所输入的key个数对上。LIMIT为可选参数,输入一个不为负的整数表示在交集结果中进行扫描元素的个数,缺省时默认为0,意味着无限,直至扫描过所有元素。
注:sintercard命令是在Redis 7.0出现的。
# 示例
127.0.0.1:6379> sadd a 1 2 3 4 5
(integer) 5
127.0.0.1:6379> sadd b 3 4 5 6 7
(integer) 5
127.0.0.1:6379> sinter a b
1) "3"
2) "4"
3) "5"
# 返回交集中元素个数
127.0.0.1:6379> sintercard 2 a b
(integer) 3
# limit有输入时限定了在结果中所扫描的元素个数,影响了返回值
127.0.0.1:6379> sintercard 2 a b limit 1
(integer) 1
127.0.0.1:6379> sintercard 2 a b limit 2
(integer) 2
127.0.0.1:6379> sintercard 2 a b limit 5
(integer) 3
# limit为0,意味着无限
127.0.0.1:6379> sintercard 2 a b limit 0
(integer) 3
13. smove命令
smove {source} {destination} {member} ,将source中的元素member弹出并移动到destination中,每次只能移动一个元素。返回值为1表示移动成功,为0表示失败。
# 示例
127.0.0.1:6379> sadd a 1 2 3
(integer) 3
127.0.0.1:6379> sadd b 4
(integer) 1
# 将集合a中的元素3移动到b
127.0.0.1:6379> smove a b 3
(integer) 1
127.0.0.1:6379> smembers b
1) "3"
2) "4"
# 尝试移动a中不存在的元素到b,返回0
127.0.0.1:6379> smove a b 5
(integer) 0
# 查看a剩下的元素
127.0.0.1:6379> smembers a
1) "1"
2) "2"
集合类型还剩下一个命令 “sscan”,在今后会把scan,hscan,sscan,zscan放在一起专门出个专题进行介绍。
下面是《Redis开发与运维》中的集合常用命令时间复杂度。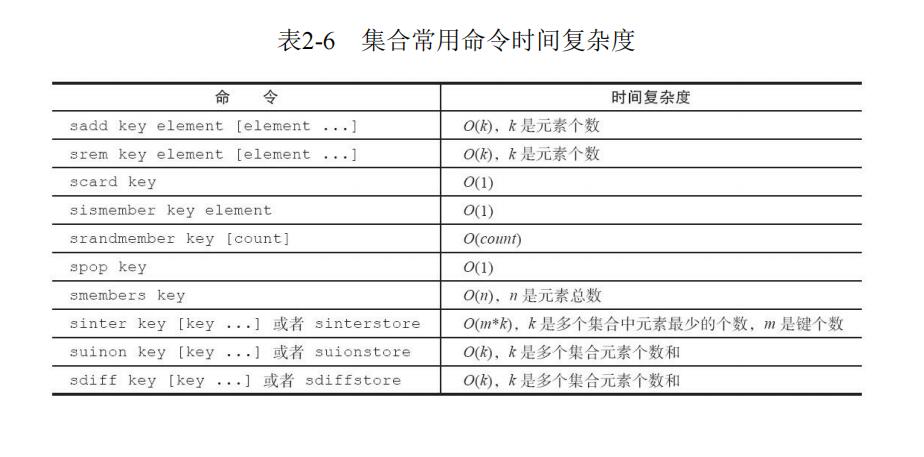
在这里补充文章中讲到的但上图中没有提到的命令时间复杂度:
3. 内部编码
# 示例
# 集合中元素都是整数
127.0.0.1:6379> sadd a 1 2 3
(integer) 3
127.0.0.1:6379> object encoding a
"intset"
# 往集合加入一个非整数元素'a'后,内部编码转换为hashtable
127.0.0.1:6379> sadd a a
(integer) 1
127.0.0.1:6379> object encoding a
"hashtable"
4. 应用场景
1. 标签(tag)
例如一个用户可能对娱乐、体育比较感兴趣,另一个用户可能对历史、新闻比较感兴趣,这些兴趣点就是标签。有了这些数据就可以得到喜欢同一个标签的人,以及用户的共同喜好的标签,这些数据对于用户体验以及增强用户黏度比较重要。例如一个电子商务的网站会对不同标签的用户做不同类型的推荐,比如对数码产品比较感兴趣的人,在各个页面或者通过邮件的形式给他们推荐最新的数码产品,通常会为网站带来更多的利益。
标签的简单实现示例如下:
# 给用户添加标签
sadd user:1:tags tag1 tag2 tag3
# 给标签添加用户
sadd tag1:users user:1 user:2 user:3
# 删除用户下的标签
srem user:1:tags tag1 tag5
# 删除标签下的用户
srem tag1:users user:1
# 计算用户共同感兴趣的标签
sinter user:1:tags user:2:tags
用户和标签的关系维护应该在一个事务内执行,防止部分命令失败造成的数据不一致。
5. 源码分析
在金毛站长翻源码的时候,发现srandmember的源码是很长的一大块,因为srandmember的使用情况具体一共可以分为4种。那么让我们挑战分析一下这一大块的源码叭。首先先来看srandmemberCommand函数的实现:
/* SRANDMEMBER [] */
void srandmemberCommand(client *c) {
robj *set;
sds ele;
int64_t llele;
int encoding;
/* 通过输入的参数个数判断该命令输入是否合法,
* 合法时client应有3个参数(srandmember, key, count)*/
if (c->argc == 3) {
srandmemberWithCountCommand(c);
return;
} else if (c->argc > 3) {
addReplyErrorObject(c,shared.syntaxerr);
return;
}
/* 以下是缺省count参数时的处理,
* 这里首先检查key是否为NULL,以及类型是否为set */
if ((set = lookupKeyReadOrReply(c,c->argv[1],shared.null[c->resp]))
== NULL || checkType(c,set,OBJ_SET)) return;
/* 通过调用setTypeRandomElement随机取出一个元素,
* 若内部编码为INTSET,元素会被赋值到llele上,
* 若内部编码为hashtable,元素会被赋值到ele上 */
encoding = setTypeRandomElement(set,&ele,&llele);
/* 根据对应的内部编码选择该返回的值,
* INTSET返回llele,hashtable返回ele */
if (encoding == OBJ_ENCODING_INTSET) {
addReplyBulkLongLong(c,llele);
} else {
addReplyBulkCBuffer(c,ele,sdslen(ele));
}
}
这是执行srandmember时的最浅的执行过程,这里的代码还是比较短的。本篇我们具体是要分析当有输入count参数时所调用的srandmemberWithCountCommand函数的源码,接下来让我们看看这个函数的源码:
void srandmemberWithCountCommand(client *c) {
long l;
unsigned long count, size;
int uniq = 1;
robj *set;
sds ele;
int64_t llele;
int encoding;
dict *d;
/* 检查count参数是否可以转换为长整型,不能则直接退出,
* 若可以转换,count的值会被赋值到变量l上 */
if (getLongFromObjectOrReply(c,c->argv[2],&l,NULL) != C_OK) return;
if (l >= 0) {
count = (unsigned long) l;
} else {
/* 当输入的count(即变量l)为负数时,先把它转成正数
* 另外uniq设为0,表示要求返回的元素不需要唯一出现 */
count = -l;
uniq = 0;
}
/* 对key是否为NULL和类型是否为SET进行检查 */
if ((set = lookupKeyReadOrReply(c,c->argv[1],shared.emptyarray))
== NULL || checkType(c,set,OBJ_SET)) return;
size = setTypeSize(set);
/* count为0时快速返回一个空数组 */
if (count == 0) {
addReply(c,shared.emptyarray);
return;
}
/* CASE 1:
* count为负数或是1,提取元素方法是:
* 返回count个随机元素,每次都对整个集合进行采样,
* 这种情况下不需要辅助数据结构,
* 这种情况是唯一需要以随机顺序返回的元素的 */
if (!uniq || count == 1) {
addReplyArrayLen(c,count);
while(count--) {
encoding = setTypeRandomElement(set,&ele,&llele);
if (encoding == OBJ_ENCODING_INTSET) {
addReplyBulkLongLong(c,llele);
} else {
addReplyBulkCBuffer(c,ele,sdslen(ele));
}
}
return;
}
/* CASE 2:
* count是正数且大于等于集合的size,
* 利用迭代方式取出每个元素并添加到数组来返回 */
if (count >= size) {
setTypeIterator *si;
addReplyArrayLen(c,size);
si = setTypeInitIterator(set);
while ((encoding = setTypeNext(si,&ele,&llele)) != -1) {
if (encoding == OBJ_ENCODING_INTSET) {
addReplyBulkLongLong(c,llele);
} else {
addReplyBulkCBuffer(c,ele,sdslen(ele));
}
size--;
}
setTypeReleaseIterator(si);
serverAssert(size==0);
return;
}
/* 对于接下来的CASE 3和CASE4我们需要一个辅助数据结构(字典) */
d = dictCreate(&sdsReplyDictType);
/* CASE 3:
* 集合的元素数量不大于count*SRANDMEMBER_SUB_STRATEGY_MUL时,
* 这是要求返回的元素数量接近集合的size的情况,
* 这种情况下我们先用原来的所有元素复制一个set,
* 然后从复制集合中减去被随机函数取到的元素,一共减去count个,
* 最后会使用该集合的元素做返回值,
* 如果我们使用像CASE 4中的自然方法,将会是非常低效的*/
if (count*SRANDMEMBER_SUB_STRATEGY_MUL > size) {
setTypeIterator *si;
/* 把所有元素加入到临时字典中 */
si = setTypeInitIterator(set);
dictExpand(d, size);
while ((encoding = setTypeNext(si,&ele,&llele)) != -1) {
int retval = DICT_ERR;
if (encoding == OBJ_ENCODING_INTSET) {
retval = dictAdd(d,sdsfromlonglong(llele),NULL);
} else {
retval = dictAdd(d,sdsdup(ele),NULL);
}
serverAssert(retval == DICT_OK);
}
setTypeReleaseIterator(si);
serverAssert(dictSize(d) == size);
/* 删除被随机取到的元素,直到达到数量要求为止 */
while (size > count) {
dictEntry *de;
de = dictGetFairRandomKey(d);
dictUnlink(d,dictGetKey(de));
sdsfree(dictGetKey(de));
dictFreeUnlinkedEntry(d,de);
size--;
}
}
/* CASE 4:
* 当count*SRANDMEMBER_SUB_STRATEGY_MUL < size 时,
* 也就是与集合的size相比count很小时,
* 简单地从集合中获取随机元素并加入到辅助字典中,
* 直至达到count个元素 */
else {
unsigned long added = 0;
sds sdsele;
dictExpand(d, count);
while (added < count) {
encoding = setTypeRandomElement(set,&ele,&llele);
if (encoding == OBJ_ENCODING_INTSET) {
sdsele = sdsfromlonglong(llele);
} else {
sdsele = sdsdup(ele);
}
/* 尝试向临时字典中添加元素,如果字典中已经
* 存在该元素就把等待添加的元素释放掉,
* 否则就添加并增加字典元素的数量 */
if (dictAdd(d,sdsele,NULL) == DICT_OK)
added++;
else
sdsfree(sdsele);
}
}
/* CASE 3 & 4: 将结果返回给用户 */
{
dictIterator *di;
dictEntry *de;
addReplyArrayLen(c,count);
di = dictGetIterator(d);
while((de = dictNext(di)) != NULL)
addReplyBulkSds(c,dictGetKey(de));
dictReleaseIterator(di);
dictRelease(d);
}
}
这是个整体有150行左右的函数,分成了4个Case部分,结合站长我写的注释大概看一下,就可以明白它们各自的执行方式了(应该叭…)。如果有兴趣继续深入了解源码的话,我建议可以看看setTypeRandomElement学习一下Redis中获取随机元素的算法哦。(反正我是没学会呜呜)
5. 杂谈之关于金毛成为了Redis Contributor
之前讲hash那期发现的hincrbyfloat奇怪现象所导致金毛的人生第一次PR,在经过了11天的等待反馈和来回改动不下十次代码之后。在一天早晨打开手机,终于看到QQ邮箱传来了我被merged的好消息!这下金毛站长终于从“准Redis contributor”成为了名正言顺的第581位Redis contributor!🍭🍭
这份PR代码的改动,从代码数量上看是从一开始的增加12行到增加5行,又到增加47行,最后定格成增加33行。从添加代码的位置上看是从hincrbyfloat和hincrby函数迁移到hashTypeSet,然后又在hash类型的单元测试文件hash.tcl里添加了专门检查此类型bug的测试代码。
Redis的leader也很厉害,考虑到了不少更远的问题,让我改了不少细节,在第一次在线给我的代码跑测试时集群测试中出现了问题,马上就想到了是我的测试代码里一个del命令删除了两个key导致的问题(在集群中两个key不一定都在同个机器上)。总之我的第一份代码有好多细节的问题,甚至比如格式上少了个空格导致没有对齐。但是Redis的leader都没有对我感到急躁,还默默地帮我加了这个空格和改了一下我直接用翻译软件弄出来的英文注释…而且就算我很菜,在我对他提议在测试field的长度超过listpack编码的限制这个代码中,把field从12345678这种纯数字改成小数的时候,我不明白,因为就算是整数也只会判断它的长度,所以对他提出了疑问。他还是很谦虚地先说我是对的,(这个命令)我们不是在增加field而是value。然后跟我解释说对于listpack这并不重要,listpack只能存储字符串或者整数,不能保存double(浮点数会转换成字符串),所以使用整数我并没有真正保存一个长字符串。所以他想在这种情况下,我应该使用abcdefg或xxxxxx而不是数字。最后他还说道”我们也许不应该过多地研究这个问题,但既然我们做了……那就做吧。“最后实际上我还是没明白,他就算提到这些,但是field即使使用了纯数字,对field的长度检查也没有影响,因为在这里已经转成Redis里的字符串类型sds了。不过当时大晚上1点了我也没想太多,刚看完他说的这些也只觉得不明觉厉,所以就照它的去改了(当时熄灯了笔记本也没电了,叫鸭神 github:tank59he 帮我commit的,感谢鸭神🍭🍭)。这就是最后一次改动,过了一个小时之后他再次启动了在线测试发现没有问题之后批准并合并了代码。
我本来想专门出一篇博客来讲讲我成为Redis contributor这11天的过程,但是我想了想,发现问题是在讲hash类型API那期的杂谈里提到了,然后上一期和这一期的杂谈都有提一点关于这个pr的事情,不是很有必要专门出一篇专题了(因为已经连载了嘻嘻)。但是如果大伙想看的话,我也会专门讲讲关于我的第一次pr更详细的事情哒。🍭🍭
set类型API大全就到这里结束啦,下一期zset类型API大全我们不见不散🍭🍭。



