Redis学习笔记(6):zset类型API大全
1. zset类型简介
zset中文名叫有序集合,有序集合相对于哈希、列表、集合来说会有一点点陌生,但既然叫有序集合,那么它和集合必然有着联系,它保留了集合不能有重复成员的特性, 但不同的是,有序集合中的元素可以排序。但是它和列表使用索引下标作为排序依据不同的是,它给每个元素设置一个分数(score)作为排序的依据。有序集合提供了获取指定分数和元素范围查询、计算成员排名等功能,合理的利用有序集合,能帮助我们在实际开发中解决很多问题。
注:有序集合里的元素虽然不能重复,但不同元素的score是可以重复的,这就好比学生学号是不同的,但是学生的考试成绩是可以相同的。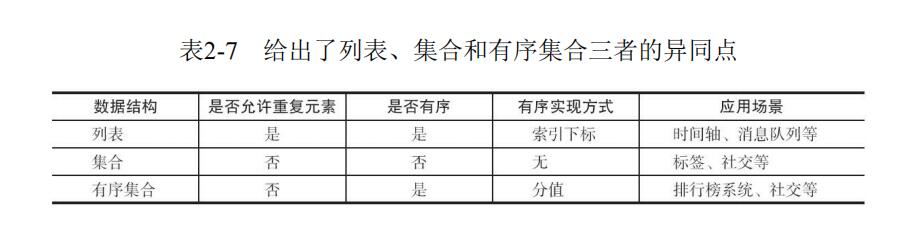
2. zset命令
zadd命令:
zadd {key} (nx|xx) (lt|gt) (ch) (incr) {score1} {member1} {score2…} {member2…} ,作用为向有序集合内添加成员,返回成功添加的元素个数。
# 示例
127.0.0.1:6379> zadd sc 100 alice 90 bob
(integer) 2
# sc已存在alice,该操作只是更新score,所以添加成功元素个数为0
127.0.0.1:6379> zadd sc 95 alice
(integer) 0
zadd有六种扩展参数:
注:nx/xx互斥,gt/lt/nx互斥,也就是不能同时使用。
zcard命令:
zcard {key} ,返回zset中的元素个数。
# 示例
127.0.0.1:6379> zadd sc 50 tom 60 jerry
(integer) 2
127.0.0.1:6379> zcard sc
(integer) 2
该命令时间复杂度是O(1)的,但注意如果把zset_max_listpack_entries调至65535(uint16_max)以上,之后有序集合是listpack且元素个数大于了65535,该时间复杂度会是O(n),因为listpack记录的元素个数最大只能到uint16_max,超出需要进行遍历统计。Redis7之前为ziplist,不过也是同理。
zscore/zmscore命令:
zscore {key} {member} ,返回key中member的分数,若不存在返回nil。
zmscore {key} {member1} {member2…} ,返回key中member的分数,支持输入多个member,若不存在返回nil。
# 示例
127.0.0.1:6379> zadd sc 50 tom 60 jerry
(integer) 2
127.0.0.1:6379> zscore sc tom
"50"
127.0.0.1:6379> zscore sc t
(nil)
# zmscore批量获取元素的分值
127.0.0.1:6379> zadd a 1 a 2 b
(integer) 2
127.0.0.1:6379> zmscore a a b
1) "1"
2) "2"
zrank/zrevrank命令:
zrank {key} {member} ,返回key中member的排名。zrank排名是从小到大的,zrevrank排名则是从大到小的,还要注意排名是从第0开始的,若不存在返回nil。
# 示例
127.0.0.1:6379> zadd sc 50 tom 60 jerry
(integer) 2
127.0.0.1:6379> zrank sc tom
(integer) 0
127.0.0.1:6379> zrank sc jerry
(integer) 1
127.0.0.1:6379> zrank sc t
(nil)
127.0.0.1:6379> zrevrank sc tom
(integer) 1
127.0.0.1:6379> zrevrank sc jerry
(integer) 0
zrem命令:
zrem {key} {member1} {member2…} ,删除key中的元素,一条命令可输入并删除多个member,返回成功删除的元素个数。
# 示例
127.0.0.1:6379> zadd sc 50 tom 60 jerry
(integer) 2
127.0.0.1:6379> zcard sc
(integer) 2
127.0.0.1:6379> zrem sc tom
(integer) 1
127.0.0.1:6379> zcard sc
(integer) 1
zincrby命令:
zincrby {key} {increment} {member} ,增加member的分数,不存在的member会被自动创建,并在0的基础上增加increment,返回增加后的分数。
# 示例
127.0.0.1:6379> zadd sc 50 tom
(integer) 1
127.0.0.1:6379> zincrby sc 5 tom
"55"
# jerry原本不存在,创建jerry
127.0.0.1:6379> zincrby sc 60 jerry
"60"
zrange/zrevrange命令
zrange {key} {min} {max} (byscore|bylex) (rev) (limit offset count) (withscores) ,缺省所有可选参数时为返回key中从按分值从小到大排序的第min到第max个元素。可选参数有:
# 示例
127.0.0.1:6379> zadd test 1 a 2 b 3 c 4 d
(integer) 4
# max为负数时表示倒数,这里是从第0个到倒数第1个,即包含了全部元素
127.0.0.1:6379> zrange test 0 -1
1) "a"
2) "b"
3) "c"
4) "d"
# withscores,带score一起返回
127.0.0.1:6379> zrange test 0 -1 withscores
1) "a"
2) "1"
3) "b"
4) "2"
5) "c"
6) "3"
7) "d"
8) "4"
# byscore,按分值[2,4]范围从小到大查询
127.0.0.1:6379> zrange test 2 4 byscore
1) "b"
2) "c"
3) "d"
# byscore + limit组合使用,offset为1,count为1,
# 即从"bcd"按起始位置(b)的偏移量(+1)挑出"c"做起始元素,共拿出1个元素
127.0.0.1:6379> zrange test 2 4 byscore limit 1 1
1) "c"
# rev,从大到小
127.0.0.1:6379> zrange test 0 -1 rev
1) "d"
2) "c"
3) "b"
4) "a"
# rev + byscore,注意使用了rev后输入的[min,max]为[max,min]
127.0.0.1:6379> zrange test 4 2 byscore rev
1) "d"
2) "c"
3) "b"
# 删除test并创建一个score全为0的新test,成员依然是a,b,c,d
127.0.0.1:6379> del test
(integer) 1
127.0.0.1:6379> zadd test 0 a 0 b 0 c 0 d
(integer) 4
# min,max为-,+,即无穷小和无穷大,结果包含所有元素
127.0.0.1:6379> zrange test - + bylex
1) "a"
2) "b"
3) "c"
4) "d"
# min为[a,结果包含a,max为(c,结果不包含c,按该字典序范围则返回a,b
127.0.0.1:6379> zrange test [a (c bylex
1) "a"
2) "b"
zrevrange {key} {start} {stop} (withscores) ,效果等同于zrange + rev,start和stop即开始和结束的下标,只有一个扩展参数withscores,上面已解释过就不再提了。zrevrange能做的事现在由于zrange有rev的扩展参数已经可以做到了,不再写使用示例了。
zrangestore命令:
zrangestore {dst} {src} {min} {max} (byscore|bylex) (rev) (limit offset count) ,缺省所有可选参数时为将src中从按分值从小到大排序的第min到第max个元素保存到dst中,并返回保存的元素个数。其余参数和zrange的相同就不再叙述。
# 示例
127.0.0.1:6379> zadd a 1 a 2 b 3 c 4 d
(integer) 4
127.0.0.1:6379> zrangestore b a 0 2
(integer) 3
127.0.0.1:6379> zrange b 0 -1
1) "a"
2) "b"
3) "c"
zcount命令:
zcount {key} {min} {max} ,返回分值范围[min,max]中的元素个数。
# 示例
127.0.0.1:6379> zadd test 1 a 2 b 3 c 4 d
(integer) 4
127.0.0.1:6379> zcount test 1 3
(integer) 3
zremrangebyrank/zremrangebyscore/zremrangebylex命令:
zremrangebyrank {key} {start} {stop} ,删除从小到大的第min到第max范围内的元素,返回删除的元素个数。
zremrangebyscore {key} {min} {max} ,删除分值范围在[min,max]范围内的元素,返回删除的元素个数。
zremrangebylex {key} {min} {max} ,注意key中所有元素score必须相同,否则不准!按字典序大小删除元素,min和max的输入为-(无穷小),+(无穷大),其余输入前面需要为[或(,如[a表示包含a,(a表示不包含a,可以理解为闭区间和开区间的符号关系。返回删除的元素个数。
# 示例
127.0.0.1:6379> zadd a 1 a 2 b 3 c 4 d
(integer) 4
127.0.0.1:6379> zremrangebyrank a 1 2
(integer) 2
127.0.0.1:6379> zrange a 0 -1
1) "a"
2) "d"
127.0.0.1:6379> zremrangebyscore a 1 4
(integer) 2
127.0.0.1:6379> zrange a 0 -1
(empty array)
127.0.0.1:6379> zadd a 0 a 0 b 0 c 0 d
(integer) 4
127.0.0.1:6379> zremrangebylex a [a (c
(integer) 2
127.0.0.1:6379> zrange a 0 -1
1) "c"
2) "d"
zpopmin/zpopmax命令:
zpopmin/zpopmax {key} (COUNT count) ,从key中删除并返回元素,zpopmin为从小到大,zpopmax为从大到小,count可选,count为要弹出元素个数,缺省为1。
# 示例
127.0.0.1:6379> zadd a 1 a 2 b 3 c
(integer) 3
127.0.0.1:6379> zpopmin a
1) "a"
2) "1"
127.0.0.1:6379> zpopmax a 2
1) "c"
2) "3"
3) "b"
4) "2"
bzpopmin/bzpopmax命令:
bzpopmin {key1} {key2…} {timeout} ,按key的输入顺序从左到右选择第一个非空的有序集合删除并返回分值最小的元素,该命令为阻塞操作,会阻塞使用该命令的客户端。timeout为超时时间,单位为秒,若为0则会无限等待直到该客户端能够取到元素为止。
# 示例
127.0.0.1:6379> zadd t1 1 a 2 b 3 c
(integer) 3
127.0.0.1:6379> zadd t2 1 d 2 e 3 f
(integer) 3
127.0.0.1:6379> bzpopmin t1 t2 0
1) "t1"
2) "a"
3) "1"
# 对不存在的t3使用bzpopmin,超时时间设置3s
127.0.0.1:6379> bzpopmin t3 3
(nil)
(3.06s)
# 消除你可能会有的误解,popmin并不是指多个key中最小score的元素(此时t2中的d最小),
# 而是从左到右第一个遇到的非空key的最小score元素
127.0.0.1:6379> bzpopmin t1 t2 0
1) "t1"
2) "b"
3) "2"
127.0.0.1:6379> bzpopmax t2 t1 0
1) "t2"
2) "f"
3) "3"
127.0.0.1:6379> bzpopmax t3 t1 1
1) "t1"
2) "c"
3) "3"
zmpop命令:
zmpop {numkeys} {key1} {key2…} {min|max} (COUNT count) ,按key的输入顺序从左到右选择第一个非空的有序集合删除并返回元素,numkeys为输入的key数量,必须要等于输入key数,否则会报错。参数为min则从最小的开始,参数为max则从最大的开始,count为弹出元素的最大数量,缺省为1。
# 示例
127.0.0.1:6379> zadd a 1 a 2 b 3 c
(integer) 3
127.0.0.1:6379> zadd b 1 d 2 e 3 f
(integer) 2
127.0.0.1:6379> zmpop 2 a b min
1) "a"
2) 1) 1) "a"
2) "1"
127.0.0.1:6379> zmpop 2 b a max count 3
1) "b"
2) 1) 1) "f"
2) "3"
2) 1) "e"
2) "2"
3) 1) "d"
2) "1"
bzmpop命令:
bzmpop {timeout} {numkeys} {key1} (key2 …) {min|max} (COUNT count) ,按key的输入顺序从左到右选择第一个非空的有序集合删除并返回元素,timeout为超时时间,单位为秒,为0则会无限等待。numkeys为输入的key数量,必须要等于输入key数,否则会报错。参数为min则从最小的开始,参数为max则从最大的开始,count为弹出元素的最大数量,缺省为1。
# 示例
127.0.0.1:6379> zadd a 1 a 2 b 3 c
(integer) 3
127.0.0.1:6379> zadd b 1 d 2 e 3 f
(integer) 3
127.0.0.1:6379> bzmpop 0 2 a b min
1) "a"
2) 1) 1) "a"
2) "1"
127.0.0.1:6379> bzmpop 0 2 b z max count 2
1) "b"
2) 1) 1) "f"
2) "3"
2) 1) "e"
2) "2"
zinter/zinterstore/zintercard命令:
zinter {numkeys} {key1} (key2 …) (WEIGHTS (weight1) (weight2 …)) (aggregate sum | min | max) (withscores) ,有序集合的交集运算。numkeys为输入的key个数,必须要和输入的key数量相同。weights为可选参数,weights后跟key数量对应的数字,从左到右以空格分隔,第n个数字代表第n个集合的score权重,默认为1。aggregate为可选参数,后面跟sum | min | max三选一,为计算交集后的汇总方式:总和 | 最小值 | 最大值。withscores为可选参数,输入后返回结果将带上每个元素的score。
zinterstore {dst} {numkeys} {key1} (key2 …) (WEIGHTS (weight1) (weight2 …)) (aggregate sum | min | max) (withscores) ,比zinter要多一个必须参数dst,该命令为将交集结果保存至有序集合dst中,若dst不存在则会创建。
zintercard {numkeys} {key1} {key2…} ,返回集合中的元素个数。
127.0.0.1:6379> zadd a 10 a 20 b 30 c
(integer) 3
127.0.0.1:6379> zadd b 10 a 20 b 30 c 40 d
(integer) 3
127.0.0.1:6379> zinter 2 a b
1) "a"
2) "b"
3) "c"
127.0.0.1:6379> zinter 2 a b withscores
1) "a"
2) "20"
3) "b"
4) "40"
5) "c"
6) "60"
# a的分值权重为1,b的分值权重为1.5计算交集
127.0.0.1:6379> zinter 2 a b weights 1 1.5 withscores
1) "a"
2) "25"
3) "b"
4) "50"
5) "c"
6) "75"
# 将b中的a分值修改为30
127.0.0.1:6379> zadd b 30 a
(integer) 0
# 按照max score汇总结果
127.0.0.1:6379> zinter 2 a b aggregate max withscores
1) "b"
2) "20"
3) "a"
4) "30"
5) "c"
6) "30"
# 将a和b的交集结果保存到c中
127.0.0.1:6379> zinterstore c 2 a b
(integer) 3
127.0.0.1:6379> zrange c 0 -1 withscores
1) "a"
2) "40"
3) "b"
4) "40"
5) "c"
6) "60"
# 计算abc交集元素个数
127.0.0.1:6379> zintercard 3 a b c
(integer) 3
# 计算a与不存在的集合non_exists的交集元素个数
127.0.0.1:6379> zintercard 2 a non_exists
(integer) 0
zunion/zunionstore命令:
zunion {numkeys} {key1} (key2 …) (WEIGHTS (weight1) (weight2 …)) (aggregate sum | min | max) (withscores) ,有序集合的并集运算。numkeys为输入的key个数,必须要和输入的key数量相同。weights为可选参数,weights后跟key数量对应的数字,从左到右以空格分隔,第n个数字代表第n个集合的score权重,默认为1。aggregate为可选参数,后面跟sum | min | max三选一,为计算并集后的汇总方式:总和 | 最小值 | 最大值。withscores为可选参数,输入后返回结果将带上每个元素的score。
zunionstore {dst} {numkeys} {key1} (key2 …) (WEIGHTS (weight1) (weight2 …)) (aggregate sum | min | max) (withscores) ,比zinter要多一个必须参数dst,该命令为将并集结果保存至有序集合dst中,若dst不存在则会创建。
# 示例
127.0.0.1:6379> zadd a 1 a 2 b
(integer) 2
127.0.0.1:6379> zadd b 2 b 3 c
(integer) 2
127.0.0.1:6379> zunion 2 a b withscores
1) "a"
2) "1"
3) "c"
4) "3"
5) "b"
6) "4"
127.0.0.1:6379> zunionstore c 2 a b weights 2 2
(integer) 3
127.0.0.1:6379> zrange c 0 -1 withscores
1) "a"
2) "2"
3) "c"
4) "6"
5) "b"
6) "8"
zdiff/zdiffstore命令:
zdiff {numkeys} {key1} (key2 …) (WEIGHTS (weight1) (weight2 …)) (aggregate sum | min | max) (withscores) ,有序集合的差集运算。numkeys为输入的key个数,必须要和输入的key数量相同。weights为可选参数,weights后跟key数量对应的数字,从左到右以空格分隔,第n个数字代表第n个集合的score权重,默认为1。aggregate为可选参数,后面跟sum | min | max三选一,为计算差集后的汇总方式:总和 | 最小值 | 最大值。withscores为可选参数,输入后返回结果将带上每个元素的score。
zunionstore {dst} {numkeys} {key1} (key2 …) (WEIGHTS (weight1) (weight2 …)) (aggregate sum | min | max) (withscores) ,比zinter要多一个必须参数dst,该命令为将差集结果保存至有序集合dst中,若dst不存在则会创建。
# 示例
127.0.0.1:6379> zadd a 1 a 2 b
(integer) 2
127.0.0.1:6379> zadd b 2 b 3 c
(integer) 2
127.0.0.1:6379> zdiff 2 a b
1) "a"
127.0.0.1:6379> zdiffstore c 2 a b
(integer) 1
127.0.0.1:6379> zrange c 0 -1
1) "a"
zrandmember命令:
zrandmember {key} (count) (withscores) ,随机返回有序集合中的元素。count为可选参数,即返回元素的最大数量,输入一个整数,可以为负数,为负数时返回的元素结果中可能有元素重复出现,返回次数为该负数的绝对值,若正数大于集合的元素总数,只返回全部元素(因为不能重复)。withscores为可选参数,即返回结果集中带上每个元素的score。
# 示例
127.0.0.1:6379> zadd a 1 a 2 b 3 c
(integer) 3
127.0.0.1:6379> zrandmember a 2
1) "b"
2) "a"
127.0.0.1:6379> zrandmember a
"a"
127.0.0.1:6379> zrandmember a 3
1) "c"
2) "b"
3) "a"
127.0.0.1:6379> zrandmember a 5
1) "c"
2) "b"
3) "a"
127.0.0.1:6379> zrandmember a 3 withscores
1) "c"
2) "3"
3) "b"
4) "2"
5) "a"
6) "1"
127.0.0.1:6379> zrandmember a -2
1) "c"
2) "b"
127.0.0.1:6379> zrandmember a -5
1) "c"
2) "b"
3) "c"
4) "b"
5) "a"
还有一些命令: zrangbyscore , zrangebylex ,zrevrangebyscore , zrevrangebylex ,这些都可以用zrange加扩展参数实现,就不再进行详细介绍,具体可以到 https://redis.io/commands/ 查看。另外还有zscan命令没讲到,scan一类的我说过会在之后专门出一篇文章讲,所以就不加在这里了。ヾ(≧▽≦*)o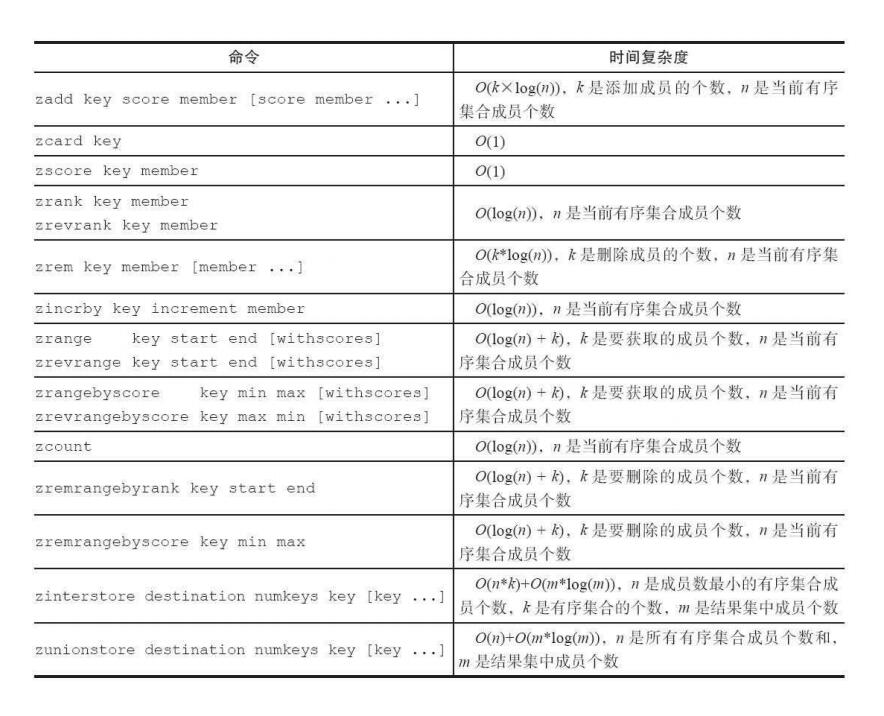
我就不再介绍其余上图没有的命令时间复杂度了,如果感兴趣的话可以到 https://redis.io/commands/ 查看你感兴趣的命令。
3. 内部编码
4. 使用场景(《Redis开发与运维》)
有序集合比较典型的使用场景就是排行榜系统。例如视频网站需要对用户上传的视频做排行榜,榜单的维度可能是多个方面的:按照时间、按照播放数量、按照获得的赞数。本节使用赞数这个维度,记录每天用户上传视频的排行榜。主要需要实现以下4个功能:
(1)添加用户赞数 例如用户mike上传了一个视频,并获得了3个赞,可以使用有序集合的 zadd和zincrby功能:
zadd user:ranking:2016_03_15 mike 3
如果之后再获得一个赞,可以使用zincrby:
zincrby user:ranking:2016_03_15 mike 1
(2)取消用户赞数 由于各种原因(例如用户注销、用户作弊)需要将用户删除,此时需要 将用户从榜单中删除掉,可以使用zrem。例如删除成员tom:
zrem user:ranking:2016_03_15 mike
(3)展示获取赞数最多的十个用户 此功能使用zrevrange命令实现:
zrevrangebyrank user:ranking:2016_03_15 0 9
此功能将用户名作为键后缀,将用户信息保存在哈希类型中,至于用户的分数和排名可以使用zscore和zrank两个功能:
hgetall user:info:tom zscore
user:ranking:2016_03_15 mike
zrank user:ranking:2016_03_15 mike
5. zrange源码分析
金毛在4000多行的zset源码中大概看了一圈之后,挑出了一个具有分析挑战性的函数源码来作为本章源码分析环节的目标。它就是zset中扩展参数最多的,通用性最高的(很多命令实际都是调用它):zrange的通用实现函数zrangeGenericCommand !
接下来先让我们看看zrangeGenericCommand的参数们:
/*
* 这个函数处理ZRANGE和ZRANGESTORE,以及不推荐使用的Z[REV]RANGE[BYPOS|BYLEX]命令
*
* 对于简单的ZRANGE和ZRANGESTORE可以在rangetype和direction参数上使用_AUTO,
* 对于其他的命令需要明确的参数值
*
* argc_start为客户端输入的命令中src key的下标,用于定位key的位置
*(这是因为不同命令的输入顺序可能是不同的,比如zrangestore dst src和zrange key)
*/
void zrangeGenericCommand(zrange_result_handler *handler, int argc_start, int store,zrange_type rangetype, zrange_direction direction)
我们可以看到它有5个入参:
接下来我们直接来看看金毛做了注释的整个源码:
void zrangeGenericCommand(zrange_result_handler *handler, int argc_start, int store,zrange_type rangetype, zrange_direction direction)
{
client *c = handler->client;
robj *key = c->argv[argc_start];
robj *zobj;
zrangespec range;
zlexrangespec lexrange;
int minidx = argc_start + 1;
int maxidx = argc_start + 2;
/* Options common to all */
/* 与所有的可选参数相关的变量 */
long opt_start = 0;
long opt_end = 0;
int opt_withscores = 0;
long opt_offset = 0;
long opt_limit = -1;
/* Step 1: Skip the <src> <min> <max> args and parse remaining optional arguments. */
/* 第一步: 跳过<src> <min> <max>,解析之后的可选参数 */
for (int j=argc_start + 3; j < c->argc; j++) {
int leftargs = c->argc-j-1; /* 剩余未解析参数个数 */
/* strcasecmp用于比较两个字符串,两个字符串相等时返回0,这里的if条件为“非zrangestore命令且解析到withscores” */
if (!store && !strcasecmp(c->argv[j]->ptr,"withscores")) {
opt_withscores = 1;
/* 条件:解析到limit且剩余未解析参数个数 >= 2(因为limit至少要跟两个参数offset和count)*/
} else if (!strcasecmp(c->argv[j]->ptr,"limit") && leftargs >= 2) {
if ((getLongFromObjectOrReply(c, c->argv[j+1], &opt_offset, NULL) != C_OK) ||
(getLongFromObjectOrReply(c, c->argv[j+2], &opt_limit, NULL) != C_OK))
{
return;
}
j += 2; /* 跳过offset和count因为上面if里的两个getLongFromObjectOrReply已经解析过 */
/* 条件:使用zrange命令解析到rev参数,则更改方向相关变量direction为ZRANGE_DIRECTION_REVERSE */
} else if (direction == ZRANGE_DIRECTION_AUTO &&
!strcasecmp(c->argv[j]->ptr,"rev"))
{
direction = ZRANGE_DIRECTION_REVERSE;
/* 条件:使用zrange命令解析到bylex参数,则更改与范围类型相关变量rangetype为ZRANGE_LEX ,下方类似*/
} else if (rangetype == ZRANGE_AUTO &&
!strcasecmp(c->argv[j]->ptr,"bylex"))
{
rangetype = ZRANGE_LEX;
} else if (rangetype == ZRANGE_AUTO &&
!strcasecmp(c->argv[j]->ptr,"byscore"))
{
rangetype = ZRANGE_SCORE;
} else {
addReplyErrorObject(c,shared.syntaxerr);
return;
}
}
/* Use defaults if not overridden by arguments. */
/* 如果代码执行到这direction或rangetype还是AUTO,则使用默认值 */
if (direction == ZRANGE_DIRECTION_AUTO)
direction = ZRANGE_DIRECTION_FORWARD;
if (rangetype == ZRANGE_AUTO)
rangetype = ZRANGE_RANK;
/* Check for conflicting arguments. */
/* 检查是否有冲突的参数(算语法错误),具体什么错误请看下方报错返回的字符串信息就可以理解了 */
if (opt_limit != -1 && rangetype == ZRANGE_RANK) {
addReplyError(c,"syntax error, LIMIT is only supported in combination with either BYSCORE or BYLEX");
return;
}
if (opt_withscores && rangetype == ZRANGE_LEX) {
addReplyError(c,"syntax error, WITHSCORES not supported in combination with BYLEX");
return;
}
/* 当direction是ZRANGE_DIRECTION_REVERSE,将原来输入参数的min和max做个交换 */
if (direction == ZRANGE_DIRECTION_REVERSE &&
((ZRANGE_SCORE == rangetype) || (ZRANGE_LEX == rangetype)))
{
/* Range is given as [max,min] */
int tmp = maxidx;
maxidx = minidx;
minidx = tmp;
}
/* Step 2: Parse the range. */
/* 第二步:解析范围类型,以下会根据你输入的命令参数分AUTO/RANK,SCORE,LEX三种情况来解析入参min,max */
switch (rangetype) {
case ZRANGE_AUTO:
case ZRANGE_RANK:
/* Z[REV]RANGE, ZRANGESTORE [REV]RANGE */
if ((getLongFromObjectOrReply(c, c->argv[minidx], &opt_start,NULL) != C_OK) ||
(getLongFromObjectOrReply(c, c->argv[maxidx], &opt_end,NULL) != C_OK))
{
return;
}
break;
case ZRANGE_SCORE:
/* Z[REV]RANGEBYSCORE, ZRANGESTORE [REV]RANGEBYSCORE */
if (zslParseRange(c->argv[minidx], c->argv[maxidx], &range) != C_OK) {
addReplyError(c, "min or max is not a float");
return;
}
break;
case ZRANGE_LEX:
/* Z[REV]RANGEBYLEX, ZRANGESTORE [REV]RANGEBYLEX */
if (zslParseLexRange(c->argv[minidx], c->argv[maxidx], &lexrange) != C_OK) {
addReplyError(c, "min or max not valid string range item");
return;
}
break;
}
if (opt_withscores || store) {
zrangeResultHandlerScoreEmissionEnable(handler);
}
/* Step 3: Lookup the key and get the range. */
/* 第三步: 查找key */
zobj = lookupKeyRead(c->db, key);
/* key不存在 */
if (zobj == NULL) {
if (store) {
handler->beginResultEmission(handler, -1);
handler->finalizeResultEmission(handler, 0);
} else {
addReply(c, shared.emptyarray);
}
goto cleanup;
}
/* key存在,但类型不为ZSET */
if (checkType(c,zobj,OBJ_ZSET)) goto cleanup;
/* Step 4: Pass this to the command-specific handler. */
/* 第四步:根据范围类型,调用专门的处理函数进行处理 */
switch (rangetype) {
case ZRANGE_AUTO:
case ZRANGE_RANK:
genericZrangebyrankCommand(handler, zobj, opt_start, opt_end,
opt_withscores || store, direction == ZRANGE_DIRECTION_REVERSE);
break;
case ZRANGE_SCORE:
genericZrangebyscoreCommand(handler, &range, zobj, opt_offset,
opt_limit, direction == ZRANGE_DIRECTION_REVERSE);
break;
case ZRANGE_LEX:
genericZrangebylexCommand(handler, &lexrange, zobj, opt_withscores || store,
opt_offset, opt_limit, direction == ZRANGE_DIRECTION_REVERSE);
break;
}
/* Instead of returning here, we'll just fall-through the clean-up. */
cleanup:
/* 如果范围类型为ZRANGE_LEX,则需要清理内存,
* 因为zlexrangespec结构体中有两个sds成员,它们创建时是动态分配 */
if (rangetype == ZRANGE_LEX) {
zslFreeLexRange(&lexrange);
}
}
以上就是zrangeGenericCommand的源码注释,如果你看完了认为这里并没有处理范围成员的过程,想继续了解一下第四步中专门的处理函数是什么样的。No problem! 金毛这就以按秩查询范围的处理函数genericZrangebyrankCommand来做个例子满足你!以下是genericZrangebyrankCommand源码注释:
/* This command implements ZRANGE, ZREVRANGE. */
/* 该函数是zrange,zevrange的实现 */
void genericZrangebyrankCommand(zrange_result_handler *handler,
robj *zobj, long start, long end, int withscores, int reverse) {
client *c = handler->client;
long llen;
long rangelen;
size_t result_cardinality;
/* Sanitize indexes. */
/* 令llen等于zobj的长度,并转换输入为负数的start和end,以及start小于0强制等于0 */
llen = zsetLength(zobj);
if (start < 0) start = llen+start;
if (end < 0) end = llen+end;
if (start < 0) start = 0;
/* Invariant: start >= 0, so this test will be true when end < 0.
* The range is empty when start > end or start >= length. */
/* 起点大于终点或起点大于总长度则范围内没有成员,在这里返回 */
if (start > end || start >= llen) {
handler->beginResultEmission(handler, 0);
handler->finalizeResultEmission(handler, 0);
return;
}
if (end >= llen) end = llen-1;
rangelen = (end-start)+1;
result_cardinality = rangelen;
handler->beginResultEmission(handler, rangelen);
if (zobj->encoding == OBJ_ENCODING_LISTPACK) {
unsigned char *zl = zobj->ptr;
unsigned char *eptr, *sptr;
unsigned char *vstr;
unsigned int vlen;
long long vlong;
double score = 0.0;
/* 定位start的位置,eptr指向start节点,同时也是指向了成员 */
if (reverse)
eptr = lpSeek(zl,-2-(2*start));
else
eptr = lpSeek(zl,2*start);
serverAssertWithInfo(c,zobj,eptr != NULL);
sptr = lpNext(zl,eptr); /* sptr指向eptr的下一个位置,也就是eptr所指向成员的score */
while (rangelen--) {
serverAssertWithInfo(c,zobj,eptr != NULL && sptr != NULL);
vstr = lpGetValue(eptr,&vlen,&vlong);
if (withscores) /* don't bother to extract the score if it's gonna be ignored. */
score = zzlGetScore(sptr);
/* 如果vstr == NULL,说明该成员的保存方式是整数,把vlong加入handler,否则加入vstr */
if (vstr == NULL) {
handler->emitResultFromLongLong(handler, vlong, score);
} else {
handler->emitResultFromCBuffer(handler, vstr, vlen, score);
}
/* reverse == true则向前定位,否则向后定位 */
if (reverse)
zzlPrev(zl,&eptr,&sptr);
else
zzlNext(zl,&eptr,&sptr);
}
} else if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {
zset *zs = zobj->ptr;
zskiplist *zsl = zs->zsl;
zskiplistNode *ln;
/* Check if starting point is trivial, before doing log(N) lookup. */
/* 判断方向,并在跳表中找到范围的第一个节点 */
if (reverse) {
ln = zsl->tail;
if (start > 0)
ln = zslGetElementByRank(zsl,llen-start);
} else {
ln = zsl->header->level[0].forward;
if (start > 0)
ln = zslGetElementByRank(zsl,start+1);
}
/* 循环将rangelen个成员加入handler的过程 */
while(rangelen--) {
serverAssertWithInfo(c,zobj,ln != NULL);
sds ele = ln->ele;
handler->emitResultFromCBuffer(handler, ele, sdslen(ele), ln->score);
ln = reverse ? ln->backward : ln->level[0].forward;
}
} else {
serverPanic("Unknown sorted set encoding");
}
/* 将范围内成员数加入到handler中 */
handler->finalizeResultEmission(handler, result_cardinality);
}
看了这么多,你看懂流程了吗?emm…没看懂也没关系,我也不是一眼看过去就懂,多花点时间反复看看代码吧。( •̀ ω •́ )✧
6. 杂谈
呼呼!终于写完了zset啊啊!zset的命令实在是太多了,源码也长(累die)!到这里Redis的五个基本数据类型的博客终于是写完了,这是一个重要的里程碑!🍭🍭
金毛现在还在筹划一个开源项目,就是对Redis7.0的源码做中文注释,共享给所有国人观看和学习(咳咳,不懂英语却懂中文的人也行)。我会先做好五个基本数据类型的源码注释:t_string.c,t_hash.c,t_list.c,t_set.c,t_zset.c,然后就放到github上,之后会继续更新,同时也希望大家都能积极来contribute你们的注释!自己一个人分析源码不如分享给大家一起看哦!!自己也会有成就感滴!🍭🍭



